|
|
| Base Unicode Version | Unicode 17.0.0 |
| Authors | Barbara Beeton David Carlisle Asmus Freytag Murray Sargent III John Wilcock |
| Date | 2025-10-02 |
| This Version | https://www.unicode.org/reports/tr25/tr25-16d2.html |
| Previous Version | https://www.unicode.org/reports/tr25/tr25-15.pdf |
| Latest Version | https://www.unicode.org/reports/tr25/ |
| Latest Proposed Update | https://www.unicode.org/reports/tr25/proposed.html |
| Revision | 16 (Draft 2) |
The Unicode Standard includes virtually all standard characters used in mathematics. This set supports a wide variety of math usage on computers, including in document presentation languages like TEX, in math markup languages like MathML and OpenMath, in internal representations of mathematics for applications like Mathematica, Maple, and MathCAD, in computer programs, and in plain text. This technical report describes the Unicode support for mathematics and gives some of the imputed default math properties for Unicode characters.
Review Note: Revisions implemented in this version of the report have primarily focused on converting the document from PDF to HTML, improving accessibility, navigation, and consistency with other Unicode Technical Reports. While these changes have been largely structural, significant content revisions are planned as the report is updated from supporting Unicode 9 to Unicode 17. This will involve incorporating new characters and properties introduced in later versions, revising examples and tables, and aligning the document with current best practices. The HTML migration lays the groundwork for these enhancements, ensuring the report remains authoritative and easier to maintain as Unicode continues to evolve.
This is a draft document which may be updated, replaced, or superseded by other documents at any time. Publication does not imply endorsement by the Unicode Consortium. This is not a stable document; it is inappropriate to cite this document as other than a work in progress.
A Unicode Technical Report (UTR) contains informative material. Conformance to the Unicode Standard does not imply conformance to any UTR. Other specifications, however, are free to make normative references to a UTR.
Please submit corrigenda and other comments with the online reporting form [Feedback]. Related information that is useful in understanding this document is found in References. For the latest version of the Unicode Standard see [Unicode]. For a list of current Unicode Technical Reports see [Reports]. For more information about versions of the Unicode Standard, see [Versions].
All of science and technology uses formulas, equations, and mathematical notation as part of the language of the subject. This report presents a discussion of the mathematics character repertoire of the Unicode Standard [Unicode] as used for mathematics, but this discussion is intended apply to mathematical notation in general.
Mathematical documents using the Arabic script use additional conventions, in particular when typesetting mathematics from right to left. Such conventions are mentioned, but not documented here. This report also does not discuss mathematical symbols of purely historical or local interest, such as symbols found in ancient mathematical texts or digits used in script-specific systems for writing numeric quantities.
As described in Unicode Technical Report #23, "The Unicode Character Property Model" [UTR23], each Unicode character has associated character properties. This report describes the properties relevant to the mathematics character repertoire, including a number of properties that are not yet part of the Unicode Standard, and details character classifications by usage and by typography. In addition, this report gives some implementation guidelines for input methods and use of Unicode math characters in programming languages.
Some of the text of the character block descriptions in the Unicode Standard was based on early drafts of this report; as a result, there is significant overlap, although the focus of the presentation is different. Unlike the information in the standard itself, the information presented here is purely informative, even where it refers to or gives added information about normative features of the standard. As always, wherever there is a discrepancy, the text of the Standard has precedence. The notational conventions follow the use in [Unicode].
Character Shapes Shown in this Report. Many of the characters referenced in this report are shown inline with character code, name, and an inline shape. Because many mathematical characters require special fonts, which may not be available on all systems, no glyph may be available to the browser when viewing or printing this report, or the glyph that is selected by the browser may be dissimilar from that shown, for example, in the Unicode code charts [Charts]. For that reason, readers are encouraged not to rely on the detailed appearance of any glyphs displayed inline. In cases of relatively rare or more recently added characters, or where some widely available fonts use glyphs that are not suitable in the context of the discussion, the report does not attempt to provide a glyph image at all. In tables and examples, bitmapped images are used.
The Unicode Standard provides a quite complete set of standard math characters to support publication of mathematics on and off the web. The early versions of Unicode, through version 3.0, already included over three hundred math-specific symbols. Unicode 3.1 introduced almost a thousand new alphanumeric symbols, and Unicode 3.2 introduced six hundred new characters for operators, arrows, and delimiters. The more limited additions to the repertoire in the versions since then have filled some gaps in coverage, in particular for mapping existing ISO entity sets for publishing [ISO9573]. Unicode 9.0 contains a total of 2310 characters that have the [Math] property (see Math property in [CharProp]).
The repertoire of mathematical characters in [Unicode] is the result of input from many sources, notably from the STIX Project (Scientific and Technical Information Exchange)[STIX], a collaborative project of scientific and technical publishers. The STIX collection includes, but is not limited to, symbols gleaned from mathematical publications by experts from the American Mathematical Society (AMS), and symbol sets provided by Elsevier Publishing, the American Physical Society (APS), the American Institute for Physics (AIP), and the Institute for Electrical and Electronics Engineers (IEEE). This repertoire enables the display of virtually all standard mathematical symbols. Nevertheless, no collection of mathematical symbols can ever be considered complete; mathematicians and other scientists are continually inventing new mathematical symbols, which will be considered for addition as they become widely accepted in the scientific communities.
Mathematical Markup Language (MathML™) [MathML], an XML application [XML] , which is built into HTML, is a major beneficiary of the increased repertoire for mathematical symbols. The W3C Math Working Group, which developed MathML, lobbied in favor of the inclusion of the new characters. In addition, the new characters lend themselves to direct plain-text encoding of mathematics for various purposes such as UnicodeMath [UTN28], which can be much more compact than MathML or TEX, the typesetting language and program designed by Donald Knuth [TEX] (see Section 4 Implementation Guidelines).
In addition to the discussion given in this section, see Mathematical operators and symbols in Unicode.
The Mathematical Alphanumeric Symbols block (U+1D400..U+1D7FF) contains a large collection of letter-like symbols for use in mathematical notation, typically for variables. The characters in this block are intended for use only in mathematical or technical notation; they are not intended for use in non-technical text. When used with markup languages, for example with MathML, the characters are expected to be used directly, instead of indirectly via entity references or by composing them from base letters and style markup.
Words Used as Variables. Sometimes whole words are used as variables, not just single letters. For word variables (see Section 2.16 Other Characters for an example and Section 3.2.1 Alphabetic), normal letters are preferred over alphanumeric symbols because the juxtaposition of single-letter variables generally implies multiplication, or some other composition, rather than word formation. Use of normal letters for word variables not only provides the necessary scoping, it also allows the use of a more extended alphabet and can be embellished by markup if desired.
Basic Set of Alphanumeric Characters. Mathematical notation uses a basic set of mathematical alphanumeric characters which consists of:
For some characters in the basic set of Greek characters, two variants of the same character are included. This is because they can appear in the same mathematical document with different meanings, even though they would have the same meaning in Greek text.
Mathematical Accents. The diacritics, or accents, in mathematical text usually have special semantic significance different from that of changing the pronunciation of a letter, as is the case for text accents. Because the use of text accents such as the acute accent would interfere with common mathematical diacritics, only unaccented forms of the letters are used for mathematical notation. Examples of common mathematical diacritics that can be confused with text accents are the circumflex, macron, or the single or double dot above, the latter two of which are commonly used in physics to denote derivatives with respect to the time variable.
Mathematical symbols with diacritics are always represented by combining character sequences, except as required by normalization. See Unicode Standard Annex #15, "Unicode Normalization Forms" [UAX15] for more information. Note that normalization leaves all characters in the Mathematical Alphanumeric Symbols and Letterlike Symbols blocks unaffected. These blocks contain nearly all alphabetic characters used as math symbols.
Additional Characters.
In addition to this basic set, mathematical notation also uses the bold upper- and lowercase digamma
(U+1D7CA and U+1D7CB), and the four Hebrew-derived characters (U+2135..U+2138), for example in
for the first transfinite cardinal. Occasional
uses of other alphabetic and numeric characters are known. Examples include U+0428 CYRILLIC CAPITAL LETTER SHA, U+306E HIRAGANA LETTER NO, the ideograph U+4E2D 中 and Eastern
Arabic-Indic digits (U+06F0..U+06F9). However, unlike the characters in the mathematical alphabets,
these characters are only used in a single, basic form. See also Arabic Mathematical Alphabets.
Dotless Characters.
In Unicode, the characters “i” and “j”, including their variations in the mathematical alphabets,
have the Soft_Dotted property. Any conformant renderer will remove the dot when the character is
followed by a nonspacing combining mark above. Therefore, using an individual mathematical italic
i or j with math accents would result in the intended display. However, in mathematical
equations an entire sub-expression can be placed underneath a math accent, for example, when a 'wide
hat' is placed on top of , as in this
example shown together with the corresponding [TEX] notation:
$$\widehat{\imath + \jmath} = \hat{\imath} + \hat{\jmath}$$
Whenever a mathematical accent applies to an entire subexpression, a renderer can no longer rely
simply on the presence of an adjacent combining character to substitute the un-dotted glyph; whether
the dots should be removed in such a situation is no longer predictable. In TEX, this decision is
left to the author, and some authors would want to use the dotted forms as in
$\widehat{i + j}$.
In some documents, mathematical italic dotless i or j are used explicitly without any
combining marks, or even in contrast to the dotted versions. Therefore, the Unicode Standard provides
the explicitly dotless characters U+1D6A4 𝚤 MATHEMATICAL ITALIC DOTLESS I
and U+1D6A5 𝚥 MATHEMATICAL ITALIC DOTLESS J. They map
to the ISOAMSO entities imath and jmath or the [TEX] macros
$\imath and $\jmath which by default are always italic.
Their appearance in the code charts is similar to the shapes documented in the ISO 9573-13 entity
sets and used by TEX. They do not form case pairs.
Where a math accent is immediately applied to these entities, as in the TEX expression
$\hat{\imath} + \hat{\jmath}$, they could be mapped to mathematical italic
i or j when converting to Unicode, but making general substitutions could result in an
unintended appearance or a change to the document.
Semantic Distinctions. Mathematical notation requires a number of Latin and Greek alphabets that initially appear to be mere font variations of one another. For example, the letter H can appear as plain or upright (), bold (), italic (), and script (). However, in any given document, these characters have distinct, and usually unrelated, mathematical semantics. For example, a normal represents a different variable from a bold , etc. If these attributes are dropped in plain text, the distinctions are lost and the meaning of the text is altered. Without the distinctions, the well-known Hamiltonian formula turns into the integral equation in the variable H:
Mathematicians will object that a properly formatted integral equation requires all the letters in this example (except perhaps for the d) to be in italics. However, because the distinction between and has been lost, they would recognize the equation as a fallback representation of an integral equation, and not as a fallback representation of the Hamiltonian. By encoding a separate set of alphabets, it is possible to preserve such distinctions in plain text.
Mathematical Alphabets. The alphanumeric symbols encountered in mathematics are given in the following table:
Table 1. Mathematical Alphabets
| Math Style | Characters from Basic Set | Location |
|---|---|---|
| plain (upright, serifed) | Latin, Greek and digits | BMP |
| bold | Latin, Greek and digits | Plane 1 |
| italic | Latin and Greek | Plane 1* |
| bold italic | Latin and Greek | Plane 1 |
| script (calligraphic) | Latin | Plane 1* |
| bold script (calligraphic) | Latin | Plane 1 |
| Fraktur | Latin | Plane 1* |
| bold Fraktur | Latin | Plane 1 |
| double-struck | Latin and digits , digits, and Arabic | Plane 1* |
| sans-serif | Latin and digits | Plane 1 |
| sans-serif bold | Latin, Greek and digits | Plane 1 |
| sans-serif italic | Latin | Plane 1 |
| sans-serif bold italic | Latin and Greek | Plane 1 |
| monospace | Latin and digits | Plane 1 |
| chancery | Latin | Plane 1* |
| roundhand | Latin | Plane 1* |
| isolated | Arabic | Plane 1 |
| initial | Arabic | Plane 1 |
| tailed | Arabic | Plane 1 |
| stretched | Arabic | Plane 1 |
| looped | Arabic | Plane 1 |
* Some of these alphabets have characters in the BMP as noted in the following section.
The plain math upright letters have been unified with the existing characters in the Basic Latin and Greek blocks. There are 24 double-struck, italic, Fraktur and script characters that already exist in the Letterlike Symbols block (U+2100..U+214F). These are explicitly unified with the characters in this block and corresponding holes have been left in the mathematical alphabets.
Compatibility Decompositions. All mathematical alphanumeric symbols have compatibility decompositions to the base Latin and Greek letters—folding away such distinctions, however, is usually not desirable as it loses the semantic distinctions for which these characters were encoded. See Unicode Standard Annex #15, "Unicode Normalization Forms" [UAX15] for more information.
Typical Uses. The following list catalogs examples of typical uses for some of these styles without intending to be exhaustive or exclusive.
Arabic Mathematical Alphabets. Arabic mathematical notation (see [Lazrek]) uses mathematical alphabets based on the Arabic script and has six mathematical styles: isolated, initial, tailed, stretched, looped, and double-struck. A summary can be found in [Benatia]. Adjacent Arabic characters ordinarily take on positional shapes, as described in Section 9.2.1, Arabic, of [Unicode]. However, for designating mathematical variables, only certain letter forms are used, and they are expected to be unaffected by adjacent characters.
Mathematicians place strict requirements on the specific fonts being used to represent mathematical variables. Readers of a mathematical text need to be able to distinguish single letter variables from each other, even when they do not appear in close proximity. They must be able to recognize the letter itself, whether it is part of the text or is a mathematical variable, and lastly which mathematical alphabet it is from.
Fraktur. The black letter style is often referred to as Fraktur or Gothic in various sources. Technically, Fraktur and Gothic typefaces are distinct designs from black letter, but any of several font styles similar in appearance to the forms shown in the charts can be used.
Math Italics. Mathematical variables are most commonly set in italic, but not all italic fonts can be used successfully. In common text fonts, the italic letter v and the Greek letter ν are not very distinct. A rounded italic letter is therefore preferred in a mathematical font, as long as it is distinct from the Greek upsilon . There are other letters which sometimes have similar shapes and require special attention to avoid ambiguity. Examples are:
| Description | Glyph | Glyph | Description |
|---|---|---|---|
| italic a | alpha | ||
| italic v (pointed) | v | nu | |
| italic v (rounded) | upsilon | ||
| script X | chi | ||
| plain Y | upsilon |
Theorems are commonly printed in a text italic font. A font intended for mathematical variables should support clear visual distinctions so that variables can be reliably separated from italic text in a theorem. Some languages have common single letter words (English a, Scandinavian i, etc.), which can otherwise be easily confused with common variables.
Hard-to-distinguish Letters. Not all sans-serif fonts allow an easy distinction between lowercase l and uppercase I, and not all monospaced (fixed width) fonts allow a distinction between the letter l and the digit 1. Such fonts are not usable for mathematics. In Fraktur, the letters I and J in particular must be made distinguishable. Overburdened Black Letter forms like I and J are inappropriate. Similarly, the digit zero must be distinct from the uppercase letter O, and the empty set must be distinct from the letter o with stroke (‘’) for all mathematical alphanumeric sets. Some characters are so similar that even mathematical fonts do not attempt to provide distinguished glyphs for them. Their use is normally avoided in mathematical notation unless no confusion is possible in a given context, for example uppercase A and uppercase Alpha (Α).
Font Support for Combining Diacritics. Mathematical equations require that characters be combined with diacritics (dots, tilde, circumflex, or arrows above are common), as well as followed or preceded by super- or subscripted letters or numbers. This requirement leads to designs for italic styles that are less inclined, and script styles that have smaller overhangs and less slant than equivalent styles commonly used for text such as wedding invitations.
Typestyle for Script Characters.
In some instances, a deliberate unification with a non-mathematical symbol has been undertaken; for
example, U+2133 ℳ SCRIPT CAPITAL M is unified with the pre-1949 symbol for
the German currency unit Mark. This unification restricts the range of glyphs that can be used
for this character in the charts. Therefore the font used for the reference glyphs in the code charts
uses a simplified ‘English Script’ style, as recommended by the American Mathematical Society. For
consistency, other script characters in the Letterlike Symbols block are now shown
in the same typestyle.
The two characters U+2113 SCRIPT SMALL L, and
U+2118 SCRIPT CAPITAL P, are not regular script characters,
despite their character names. The latter is the symbol for the Weierstrass elliptic function,
a calligraphic letter shape based on the small p, and the former is derived from a special italic
letter shape called an 'ell', and is unified with the common non-SI symbol for the liter [SI]. The characters U+1D4C1 MATHEMATICAL SCRIPT SMALL L and U+1D4AB MATHEMATICAL SCRIPT CAPITAL P are the preferred characters for the script style.
Double-struck Characters. The double-struck glyphs shown in earlier editions of the standard attempted to match the design used for all the other Latin characters in the standard, which is based on Times. The current set of fonts for use in the character code charts was prepared after consultation with the American Mathematical Society and leading publishers of mathematics, and shows much simpler forms that are derived from the forms written on a blackboard. However, this font represents just one possible representation of double-struck characters; both serifed and non-serifed forms can be used in mathematical texts, and inline fonts are found in works published by certain publishers. Some fonts differ in which strokes of a glyph to double, for example the left or right leg of the uppercase A. There is no intention to support any of these stylistic preferences via character encoding, therefore only one set of double-struck mathematical alphanumeric symbols is encoded.
With Unicode 3.0 and the concurrent second edition of ISO/IEC 10646-1, the representative glyphs
for U+03C6 GREEK LETTER SMALL PHI and
U+03D5 GREEK PHI SYMBOL were exchanged. In ordinary
Greek text, the character is used exclusively, although this character
has considerable glyphic variation, sometimes represented with a glyph more like the
representative glyph shown for (, the “loopy” form) and less often with
a glyph more like the representative glyph shown for U+03D5 (, the
“straight“ form). See the Greek
table in the character code charts [Charts].
For mathematical and technical use, the straight form of the small
phi is an important symbol (TEX
\phi) and needs to be consistently
distinguishable from the loopy form (TEX
\varphi). The straight form phi
glyph is used as the representative glyph for the phi symbol at
U+03D5 to satisfy this distinction.
The assignment of representative glyphs was reversed in versions of the Unicode Standard prior to Unicode 3.0. As a result, the character explicitly identified as the mathematical symbol did not have the straight form of the character that is the preferred glyph for that use. Furthermore, it made it unnecessarily difficult for general purpose fonts supporting ordinary Greek text to also add support for Greek letters used as mathematical symbols, because many of those fonts already used the loopy form glyph for U+03C6, as preferred for Greek body text. To support the phi symbol as well, they would have had to disrupt glyph choices already optimized for Greek text.
When mapping symbol sets or XML entities to the Unicode Standard, it is important to make sure that codes or entities that require the straight form of the phi symbol be mapped to U+03D5 and not to U+03C6. Mapping to the latter should be reserved for codes or entities that represent the small phi as used in ordinary Greek text or when a contrastive phi is needed.
Fonts used primarily for Greek text may use either glyph form for U+03C6, but fonts that also intend to support technical use of the Greek letters should use the loopy form to contrast with the straight form used for U+03D5.
In Unicode 3.2 the representative glyphs for U+2278 ≸ NEITHER LESS-THAN NOR GREATER-THAN and U+2279 ≹ NEITHER GREATER-THAN NOR LESS-THAN were changed from using a vertical cancellation to
using a slanted cancellation to match the long standing canonical decompositions for these
characters, which use U+0338 ̸ COMBINING LONG SOLIDUS OVERLAY.
Irrespective of this change to the representative glyphs, the symmetric forms using the vertical
stroke remain acceptable glyph variants. Using U+2276 or
U+2277 followed by U+20D2 COMBINING LONG VERTICAL LINE OVERLAY represents these upright variants
explicitly.
Except for those fonts created with the intention to add support for both forms (via combination of U+2276 or U+2277 with U+20D2 for the upright forms) there is no need to revise the glyphs for U+2278 and U+2279: the glyphic range implied by using these character codes encompasses both shapes.
Mathematical characters can be located by looking in the code charts [Charts] at the blocks listed below or by checking the Unicode MATH property, which is assigned to characters that naturally appear in mathematical contexts (see Section 3 Mathematical Character Properties). In the text of this report, all block names are linked to their corresponding online code chart. Mathematical characters can be found in the following blocks:
Table 2. Locations of Mathematical Characters
| Block Name | Range | Character Types |
|---|---|---|
| Basic Latin | U+0021–U+007E | Variables, operators, digits* |
| Greek and Coptic | U+0370–U+03FF | Variables* |
| General Punctuation | U+2000–U+206F | Spaces, Invisible operators* |
| Letterlike Symbols | U+2100–U+214F | Variables* |
| Arrows | U+2190–U+21FF | Arrows, arrow-like operators |
| Mathematical Operators | U+2200–U+22FF | Operators |
| Miscellaneous Technical | U+2300–U+23FF | Braces, operators* |
| Geometrical Shapes | U+25A0–U+25FF | Symbols |
| Misc. Mathematical Symbols-A | U+27C0–U+27EF | Symbols and operators |
| Supplemental Arrows-A | U+27F0–U+27FF | Arrows, arrow-like operators |
| Supplemental Arrows-B | U+2900–U+297F | Arrows, arrow-like operators |
| Misc. Mathematical Symbols-B | U+2980–U+29FF | Braces, symbols |
| Suppl. Mathematical Operators | U+2A00–U+2AFF | Operators |
| Misc. Symbols and Arrows | U+2B00–U+2BFF | Arrows, operators, symbols |
| Mathematical Alphanumeric Symbols | U+1D400–U+1D7FF | Variables and digits |
| Arabic Math. Alphabetic Symbols | U+1EE00–U+1EEFF | Variables and functions |
| Geometric Shapes Extended | U+1F780–U+1F7FF | Symbols |
| Other blocks | … | Characters for occasional use |
* This block contains non-mathematical characters as well.
Some Greek letters are encoded elsewhere as technical symbols.
These include U+00B5 MICRO SIGN, U+2126 OHM SIGN, and several characters among the APL functional symbols in the
Miscellaneous Technical block.
U+03A9 GREEK LETTER CAPITAL OMEGA is the canonical
equivalent of U+2126 and its use is preferred. Micro sign is
included in several parts of ISO/IEC 8859, and therefore supported in many legacy environments where
U+03BC GREEK LETTER SMALL MU is not available.
Implementations therefore need to be able to recognize the micro sign, even though
U+03BC is the preferred character in a Unicode context.
Latin letters duplicated include U+212A KELVIN SIGN and
U+212B ANGSTROM SIGN. As in the case of the ohm sign
the corresponding regular Latin letters are canonical equivalents, therefore their use is preferred.
The left and right angle brackets at U+2329 and U+232A have long been canonically equivalent with the CJK punctuation characters “” and “” (U+3008 and U+3009). Canonical equivalence implies that the use of the latter code points is preferred and can be substituted at any time. As a consequence, not only 3008 and 3009 but also the characters 2329 and 232A U+3008 and U+3009 but also the characters U+2329 and U+232A are ‘wide’ characters. See Unicode Standard Annex #11, "East Asian Width" [UAX11]. Unicode 3.2 added two new mathematical angle bracket characters and (U+27E8 and U+27E9) that are unequivocally intended for mathematical use and should be used instead of U+2329 and U+232A.
Mathematical characters are often enhanced via use of combining marks in the ranges U+0300..U+036F and the combining marks for symbols in the range U+20D0..U+20FF. These characters follow the base characters as in non-mathematical Unicode text. This section discusses these characters and preferred ways of representing accented characters in mathematical expressions. If a span of characters is enhanced by a combining mark, for example, a tilde over AB, typically some kind of higher-level markup is needed as is done in [MathML]. Unicode does include some combining marks that are designed to be used for pairs of characters, for example, U+0360..U+0362. However, their use for mathematical text is not encouraged.
For some mathematical characters, such as many negated relations, there are multiple ways of expressing the character: as precomposed or as a sequence of base character and combining mark (see also Section 2.17 Negations). Having only a single way to represent any given character would simplify recognizing the character in searches and other manipulations. Selecting a unique representation among multiple equivalent representations is called normalization. Unicode Standard Annex #15, "Unicode Normalization Forms" [UAX15] discusses the subject in detail; however, due to requirements of non-mathematical software, not all the normalization forms presented there are ideal from the perspective of mathematics.
Ideally, one always uses the shortest form of a math operator symbol wherever possible. So
U+2260 should be used for the not equal sign instead of the
combining sequence <003D, 0338>. If a negated operator lacking a precomposed form is needed,
U+0338 COMBINING LONG SOLIDUS OVERLAY or
U+20D2 COMBINING VERTICAL LONG OVERLAY can be used to
indicate negation. This approach concurs with Normalization Form C (NFC), which is also the preferred
normalization form for use on the web.
On the other hand, for accented alphabetic characters used as variables, ideally only decomposed sequences are used, because mathematics uses a multitude of combining marks that greatly exceeds the predefined composed characters in Unicode. Accordingly, it is better to have the math display facility handle all of these cases uniformly to give a consistent look between characters that happen to have a fully composed Unicode character and those that do not. The combining character sequences also typically have semantics as a group, so it is useful to be able to manipulate and search for them individually without the need for special tables to decompose characters for this purpose. Since there are no precomposed math alphanumeric symbols, this approach concurs with Normalization Form C, except for the upright alphabetic characters (ASCII letters).
To facilitate interchange on the web, accented characters should conform to NFC when interchanged. However, to achieve consistent results, a mathematical display system should transiently decompose any precomposed upright letters when used in mathematical expressions, and should use a single algorithm to place embellishments.
Normalization Form D (NFD) uses the opposite approach from NFC. It works naturally for mathematical use of alphabetic characters, but does not use the shortest encoding of math operator symbols, making it less attractive. The other two normalization forms NFKC and NFKD remove the distinction between math alphanumeric alphabets, mapping all of them to plain ASCII or Greek characters. As a result they would destroy the semantics of many mathematical expressions, and should never be used with mathematical texts.
The Mathematical Operators (U+2200..U+22FF), Miscellaneous Mathematical Symbols-A (U+27C0..U+27FF), Miscellaneous Mathematical Symbols-B (U+2980..U+29FF), and Supplemental Mathematical Operators (U+2A00..U+2AFF) contain many mathematical operators, relations, geometric symbols and other symbols with special usages confined largely to mathematical contexts. In addition to the characters in these blocks, mathematical operators are also found in Basic Latin (ASCII) and Latin-1 Supplement. A few of the symbols from Miscellaneous Technical and characters from General Punctuation are also used in mathematical notation. The allocation of any operator to a particular block is rarely significant.
Semantics.
Mathematical operators often have more than one meaning in different subdisciplines or different
contexts. For example, the “” symbol normally denotes addition in a mathematical
context but might refer to concatenation in a computer science context dealing with strings, or
incrementation, or have any number of other functions in given contexts. Therefore, the Unicode
Standard only encodes a single character for a single symbolic form. There are numerous other instances
in which several semantic values can be attributed to the same Unicode value. For example,
U+2218 RING OPERATOR may be the equivalent of white
small circle or composite function or APL jot. The Unicode Standard does not
attempt to distinguish all possible semantic values that may be applied to mathematical operators or
relational symbols. It is up to the application or user to distinguish such meanings according to the
appropriate context. Where information is available about the usage (or usages) of particular
symbols, it is indicated in the character annotations in the code charts printed in [Unicode] and in the online code
charts
[Charts]. For more information on operator semantics,
see Glossary of mathematical symbols.
Similar Glyphs. The Standard includes many characters that appear to be quite similar to one another, but that may convey different meaning in a given context. On the other hand, mathematical operators, and especially relation symbols, may appear in various standards, handbooks, and fonts with a large number of purely graphical variants. Where variants were recognizable as such from the sources, they were not encoded separately.
For relation symbols, the choice of a vertical or forward-slanting stroke typically seems to be an aesthetic one, but both slants might appear in a given context. However, a back-slanted stroke almost always has a distinct meaning compared to the forward-slanted stroke. See Section 2.18 Variation Selector for more information on some particular variants.
Unifications.
Mathematical operators such as implies and if and only if have been unified with the
corresponding arrows (U+21D2 RIGHTWARDS DOUBLE ARROW and
U+2194 LEFT RIGHT ARROW, respectively) in the
Arrows block. Sometimes if and
only if is represented by U+21D4 LEFT RIGHT DOUBLE ARROW or is abbreviated to “iff”.
The operator U+2208 ELEMENT OF is occasionally rendered
with a taller shape than shown in the code charts. Mathematical handbooks and standards treat these
characters as variants of the same glyph. U+220A SMALL ELEMENT OF is a distinctively small version of the element of that originates in
mathematical pi fonts. (Its glyph should be upright, not slanted.)
The operators U+226B MUCH GREATER-THAN and U+226A MUCH LESS-THAN are sometimes rendered in a nested
shape, but the Unicode Standard provides a single encoding for each operator.
A large class of unifications applies to variants of relation symbols involving equality,
similarity, and/or negation. Variants involving one- or two-barred equal signs, one- or
two-tilde similarity signs, and vertical or slanted negation slashes and negation
slashes of different lengths are not separately encoded. Thus, for example, U+2288 NEITHER A SUBSET OF NOR EQUAL TO, is the archetype
for at least six different glyph variants noted in various collections.
In a few exceptional instances, essentially stylistic variants are separately encoded because the
need for round trip character mapping to other standards that distinguish the two forms.
Examples include U+2265 GREATER-THAN OR EQUAL TO, which is
distinguished from U+2267 GREATER-THAN OVER EQUAL TO; the
same distinction applies to U+2264 LESS-THAN OR EQUAL TO and
U+2266 LESS-THAN OVER EQUAL TO.
Greek-Derived Operators.
Several mathematical operators derived from Greek characters have been given separate encodings
because they are used differently than the corresponding letters. These operators may occasionally
occur in context with Greek-letter variables. They include U+2206 INCREMENT, U+220F N-ARY PRODUCT, and U+2211 N-ARY SUMMATION. The latter two are large operators
that take limits. Some typographical aspects of operators are discussed in
Section 3.2 Classification by Typographical Behavior. For example, the n-ary operators
are distinguished from letter variables by their larger size and the fact that they take limit
expressions.
Minus sign.
U+2212 MINUS SIGN is the preferred representation of the
unary and binary minus sign rather than the ASCII-derived U+002D HYPHEN-MINUS, because minus sign is unambiguous and because it is rendered with a
more desirable length, usually longer than a hyphen.
Miscellaneous Symbols.
The range from U+22EE VERTICAL ELLIPSIS to U+22F1 DOWN RIGHT DIAGONAL ELLIPSIS contains a set of
ellipses used in matrix notation. The U+22EF MIDLINE HORIZONTAL ELLIPSIS is also usually used instead of the U+2026 HORIZONTAL ELLIPSIS when the ellipsis follows a binary operator as in the expression
(see also ).
U+2023 TRIANGULAR BULLET and U+25B8 BLACK RIGHT-POINTING SMALL TRIANGLE are not intended to be distinct in
appearance. For historical reasons these two are encoded separately and not made canonical
equivalents of each other. U+25B8 BLACK RIGHT-POINTING SMALL TRIANGLE is the preferred character.
Sometimes, specific glyph forms are chosen by notational style or are needed for contrast with other
notation in the same document. For example, the symbol U+2205 EMPTY SET can be found in its slashed zero-shaped glyph form
in documents typeset in TeX, using the command \emptyset, or in contexts where it
is contrasted with the semantically distinct slashed digit zero.
For this and certain other well-established glyph variants of mathematical symbols, standardized variation sequences were added to the Unicode Standard. Thus, for example, the standardized variation sequence <U+2205, U+FE00> can be used to represent the variant of the empty-set symbol. To avoid the misuse of that sequence for the glyph variant of the digit zero with a short diagonal stroke “0”, the standardized variation sequence <U+0030, U+FE00> was separately specified for that digit glyph variant.
The Superscripts and Subscripts
block (U+2070..U+209F) together with U+00B2 SUPERSCRIPT TWO, U+00B3 SUPERSCRIPT THREE, and U+00B9 SUPERSCRIPT ONE contain a collection of superscript
and subscript digits and punctuation that can be useful in mathematics. If they are used, it is
recommended that they be displayed with the same font size as other subscripts and superscripts at
the corresponding nested script level. For example,
and a<super>2</super> should be displayed the same. However, these
subscript/superscript characters are not used in MathML or TEX and their use with XML
documents for mathematical use is discouraged. Editors for these formats may offer facilities to
convert these characters to regular characters plus markup.
Parsing of Superscript and Subscript Digits. Unlike regular digits the superscript and subscript digits have not been given the General Category property of Decimal_Digit (Nd). This prevents expressions like 2³ from being interpreted as 23 by simplistic numeric parsers. More sophisticated numeric parsers, such as general mathematical expression parsers, can nevertheless choose to identify these compatibility superscript and subscript characters as digits and interpret them appropriately within their own scope.
Arrows are used for a variety of purposes in mathematics and elsewhere, such as to imply directional relation, to show logical derivation or implication, and to represent the cursor control keys. Accordingly Unicode includes a fairly extensive set of arrows in the Arrows block U+2190..U+21FF, Supplemental Arrows-A U+27F0..U+27FF, Supplemental Arrows-B U+2900..U+297F, Miscellaneous Symbols and Arrows U+2B00..U+2BFF and Supplemental Arrows-C U+1F800..U+1F8FF, many of which appear in mathematics. It does not attempt to encode every possible stylistic variant of arrows separately, especially where their use is mainly decorative. For most arrow variants, the Unicode Standard provides encodings in the two horizontal directions, often in the four cardinal directions. For the single and double arrows, the Unicode Standard provides encodings in eight directions.
Unifications.
Arrows expressing mathematical relations have been encoded in the Arrows block U+2190..U+21FF. An
example is U+21D2 RIGHTWARDS DOUBLE ARROW, which may be
used to denote implies. Where available, such usage information is indicated in the
annotations to individual characters in Chapter 24, About the Code Charts of
[Unicode], and in the online
code charts
[Charts].
Long Arrows. The long arrows encoded in the range U+27F5..U+27FF map to standard SGML entity sets supported by MathML. Long arrows represent distinct semantics from their short counterparts, rather than mere stylistic glyph differences. For example, the shorter forms of arrows are often used in connection with limits, whereas the longer ones are associated with mappings. The use of the long arrows is so common that they were assigned entity names in the ISOAMSA entity set, one of the suites of mathematical symbol entity sets covered by the Unicode Standard.
The mathematical white square brackets, angle brackets, and double angle brackets encoded at U+27E6..U+27EB are intended for ordinary use of these particular bracket types. They are unambiguously narrow, are for use in mathematical and scientific notation, and should be distinguished from the corresponding wide forms of white square brackets, angle brackets, and double angle brackets used in CJK typography. (See the CJK Symbols and Punctuation block.)
For ordinary tortoise-shell brackets, the use of U+2772 LIGHT LEFT TORTOISE SHELL BRACKET ORNAMENT and U+2773 LIGHT RIGHT TORTOISE SHELL BRACKET ORNAMENT is recommended for mathematical use, instead of the CJK
Punctuation characters at U+3014 and U+3015. In this instance [Unicode] relaxes
the constraint on the design of the Dingbats block, which is that glyphs
for characters in this block are intended to match the design of the popular Zapf Dingbats.
The set of lenticular brackets in the CJK Punctuation block has not been duplicated because mathematical use has not yet been demonstrated, although they are used in Unicode Technical Note #28, "UnicodeMath, A Nearly Plain-Text Encoding of Mathematics" [UTN28]. Fonts containing 'wide glyphs' for these characters that include white space padding, are unsuitable for mathematical or other non-CJK use.
Deprecated Delimiters.
The angle brackets formerly aliased as “bra” and “ket”, U+2329 LEFT-POINTING ANGLE BRACKET and U+232A RIGHT-POINTING ANGLE BRACKET, are now deprecated for use with mathematics because their canonical
equivalence to CJK angle brackets is likely to result in unintended wide spacing problems when used
in mathematical formulae. Instead, one should use U+27E8 MATHEMATICAL LEFT ANGLE BRACKET and U+27E9 MATHEMATICAL RIGHT ANGLE BRACKET, respectively.
Horizontal Delimiters. Delimiters are often used horizontally, where they expand to the width of the expression they encompass, as in this example from [TEX].
\overbrace{x+\cdots+x}^{k\;\mathrm{times}}
|
|
\underbrace{x+y+z}_{>\,0}
|
By providing character codes for these delimiters, mathematical layout systems can be designed so that both regular and horizontal delimiters are encoded as characters, with markup designating the scope where necessary. When the horizontal mathematical brackets are used, all other letters, symbols and digits remain upright as illustrated in the example above. Table 3 lists the Unicode characters for horizontal delimiters.
Table 3. Horizontal Delimiters
| Code | Glyph | Description |
|---|---|---|
| U+23B4 | TOP SQUARE BRACKET | |
| U+23B5 | BOTTOM SQUARE BRACKET | |
| U+23DC | TOP PARENTHESIS | |
| U+23DD | BOTTOM PARENTHESIS | |
| U+23DE | TOP CURLY BRACKET | |
| U+23DF | BOTTOM CURLY BRACKET | |
| U+23E0 | TOP TORTOISE SHELL BRACKET | |
| U+23E1 | BOTTOM TORTOISE SHELL BRACKET |
Use of horizontal delimiters is different from horizontal display of delimiters in vertical layout of
East Asian text, where ideographic characters remain upright, but non-ideographic characters (letters,
digits) are rotated 90°. For example, the parentheses in the vertical text in Figure 1 have very different rendering from the under/overbrace
examples above.
Figure 1. Example of parentheses in vertical text

The CJK Compatibility Forms U+FE35 through U+FE39 have shapes that are superficially similar to the horizontal
delimiters, but these characters are not mathematical and have quite different rendering
requirements. They are encoded for compatibility with character sets that use explicit character
codes for the vertical glyph variants of punctuation characters. Like other CJK punctuation, CJK
Compatibility Forms have the East_Asian_Width [UAX11] property of W (wide) and are
typically implemented in one half of an EM square, with the other half empty. Layout algorithms using
these characters predict the empty half cell based on the character code, and reduce intercharacter
spacing accordingly in some circumstances.
Floors and Ceilings. Ideal forms of floors and ceilings are shaped like tall sans-serif L shapes, with their horizontal and vertical reflections appropriately translated about, with floors extending below the baseline and ceilings ending at about cap height. Stroke width tends to be uniform. The horizontal foot is short, but not too short. It should be noted that because mathematical notation uses these symbols in distinction to both square brackets and ordinary (quine) corners, adherence to these specifications is critical to allow unambiguous recognition.
Vertical lines. There are two series of characters that consist of one or more vertical lines, and that have specific use in mathematics. These are shown in Table 4.
Table 4. Vertical Lines
| Usage | Description |
|---|---|
| Delimiters |
U+007C | VERTICAL LINE (1 line)U+2016 ‖ DOUBLE VERTICAL LINE (2 lines)U+2980 ⦀ TRIPLE VERTICAL BAR DELIMITER (3 lines) |
| Operators |
U+2223 ∣ DIVIDES (1 line)U+2225 ∥ PARALLEL TO (2 lines)U+2AF4 ⫴ TRIPLE VERTICAL BAR BINARY RELATION (3 lines)U+2AFC ⫼ LARGE TRIPLE VERTICAL BAR OPERATOR (3 lines) |
The first set are used for delimiters or “fenceposts,” as in , , , or in mathematical layout they increase in size as the expression gets taller. The naming of U+2980 is a bit unfortunate in that it substitutes BAR for LINE. The characters in the second set are operators; they always occur between two elements, as in , , or . They too should be able to get taller if the elements they’re between happen to be something like fractions, but the semantics and spacing are quite different from the others. The large form is used as an n-ary operator.
The basic geometric shapes (circle, square, triangle, diamond, and lozenge) are used for a variety of purposes in mathematical texts. Because their shapes are distinct and they are easily available in multiple sizes from a variety of widely available fonts, they are also often used in an ad-hoc manner. In Unicode they are encoded in the Geometrical Shapes, Miscellaneous Technical, Block Elements, Miscellaneous Symbols, Miscellaneous Symbols and Arrows and Geometric Shapes Extended blocks as shown in Table 5.
Ideal Sizes. Mathematical usage requires at least four distinct sizes of certain simple shapes, and sometimes more. The size gradation must allow each size to be recognized, even when it occurs in isolation. In other words, shapes of the same size should ideally have roughly the same visual “impact” as opposed to same nominal height or width or exactly the same area.
For mathematical usage simple shapes ideally share a common center. Figure 2 shows the ideal size relationship across shapes of the same nominal size.
Figure 2. Size relationships across shapes of the same nominal size

The precise sizes and shapes chosen, however, are a matter for the font designer. Note that neither the current set of representative glyphs in the standard nor the glyphs from many commonly available non-mathematical fonts achieve the ideals set forth here.
Suggested Sizes. The intended sizes of existing characters and their names in [Unicode] as shown in the code charts are not always consistent. The suggested sizes here correspond to a geometric progression where for each size all characters have the same visual impact. Shapes for which only one of the columns with a “default” size exists can be implemented either as regular or medium size. The former is shown here, the latter may be more suitable for mathematical work. Table 5 summarizes the available sizes for a given symbol.
Table 5. Sizes of Simple Shapes
| shape | tiny | very small | slightly small |
small (Bullet) |
medium small | medium (default1) |
regular (default2) |
large | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| triangle left |
25C2 |
25C3 |
2BC7 * |
25C0 |
25C1 |
|||||||||
| triangle right |
25B8 2023 |
25B9 |
2BC8 * |
25B6 |
25B7 |
|||||||||
| triangle up |
25B4 |
25B5 |
2BC5 * |
25B2 |
25B3 |
|||||||||
| triangle down |
25BE |
25BF |
2BC6 * |
25BC |
25BD |
|||||||||
| square |
1F78C * |
2B1D |
2B1E |
1F78D |
25AA |
25AB |
25FE |
25FD |
25FC |
25FB |
25A0 |
25A1 |
2B1B |
2B1C |
| diamond |
1F797 * |
1F798 * |
2B29 |
22C4 |
1F799 * |
2B25 |
2B26 |
25C6 |
25C7 |
|||||
| lozenge |
1F79D * |
1F79E * |
2B2A |
2B2B |
1F79F * |
2B27 |
2B28 |
29EB |
25CA |
|||||
| pentagon up |
2B1F |
2B20 |
||||||||||||
| pentagon right |
2B53 |
2B54 |
||||||||||||
| pentagon down |
2BC2 * |
|||||||||||||
| hexagon horiz. |
2B23 |
2394 |
||||||||||||
| hexagon vertical |
2B22 |
2B21 |
||||||||||||
| octagon horiz. |

2BC3 * |
|||||||||||||
| octagon vertical |

2BC4 * |
|||||||||||||
| five pointed star |
2B51 |
2B52 |
22C6 |
2B50 |
2605 |
2606 |
||||||||
| ellipse horiz. |
2B2C |
2B2D |
||||||||||||
| ellipse vertical |
2B2E |
2B2F |
||||||||||||
| circle |
22C5 |
2219 00B7 |
2218 |
1F784 |
2022 |
25E6 |
2981 |
26AC |
26AB |
26AA |
25CF |
25CB |
2B24 |
25EF |
| circled circles |
2299 |
2609 |
233E |
|||||||||||
| circled circles |
2A00 |
29BF |
229A |
29BE |
25C9 |
25CE |
||||||||
* Some of the characters shown in this table are not available in common math fonts and the presentation shown here does not use the Unicode character indicated, but a scaled version of a different character, or an SVG representation.
Most simple geometrical shapes exist in both black and outline (white) form in a single default size. The default size as shown in the code charts would be in the column marked “regular”, while for many font implementations, a size corresponding to the column marked “medium” is chosen. As it is difficult to distinguish higher-order polygons at smaller sizes, size distinctions for such shapes are less useful for notational purposes. Triangles exist in two sizes, a default size and a small, bullet size. Lozenges and diamonds exist in a default size, an intermediate size and a bullet size. Squares and circles exist in black and white in all sizes from very small to large. There is also a tiny circle, essentially a centered dot. At the tiny size, distinction between different shapes, or black and outline forms, becomes impossible.
Arrangement in Code Space. For circles in particular, but also for lozenges, diamonds and stars, the white and black forms are not encoded under matching names or close together. The series of circled circles is also distributed across the Unicode code space.
Sizes of Derived Shapes.
Circled and squared operators and similar derived shapes are more constrained in their usage than
“plain” geometric shapes. They tend to occur in two generic sizes based on function: a smaller size
for binary operators and large size for n-ary operators. Other than circled circles, they are not
shown here. Circled circles come in two series, based on the size of the enclosing circle. The set of
circled circles may be extended by the use of U+20DD COMBINING ENCLOSING CIRCLE.
Orientation.
Some geometric shapes can exist in more than one orientation. For triangles, the Unicode Standard
encodes the four principal directions. Ovals, pentagons and hexagons exist in two orientations;
U+2394 SOFTWARE FUNCTION SYMBOL can be used as a horizontal
white hexagon. The choice of right-pointing pentagon is based on its use as an avatar of the unit
pentagon on the complex plane. Generic use in geometry would use the upright orientation.
Positioning. For a mathematical font, the centerline should go through the middle of a parenthesis, which should go from bottom of descender to top of ascender. This is the same level as the minus or the middle of the plus and equal signs. For correct positioning, the glyph will descend below the baseline for the larger sizes of the basic shapes as in Figure 3:
Figure 3. Glyph size in relation to the baseline

The standard triangles used for mathematics are also center aligned. This differs from the positioning for the representative glyphs shown in the charts, which are often based on existing non-mathematical fonts. Therefore, mathematical fonts may need to deviate in positioning of these triangles.
Other symbols used in mathematics are contained in the Miscellaneous Technical block (U+2300..U+23FF), the Geometric Shapes block (U+25A0..U+25FF), the Miscellaneous Symbols block (U+2600..U+267F), and the General Punctuation block (U+2000..U+206F).
Generally, any easily recognized and distinct symbol is fair game for mathematicians faced with the
need of creating notations for new fields of mathematics. For example, the card suits,
U+2665 BLACK HEART SUIT, U+2660 BLACK SPADE SUIT, etc., can be found as operators and as subscripts.
The characters from the Miscellaneous
Technical block in the range U+239B..U+23B3, plus U+23B7, comprise a set of bracket and other
symbol fragments for use in mathematical typesetting. These pieces originated in older font standards
and were used in past mathematical processing as characters in their own right to assemble extra-tall
glyphs for enclosing multi-line mathematical formulae. Mathematical fences are ordinarily sized to
the content that they enclose. However, in creating a large fence, the glyph is not scaled
proportionally; in particular the displayed stem weights must remain compatible with the accompanying
smaller characters. Thus, simple scaling of font outlines cannot be used to create tall brackets.
Instead, a common technique is to build up the symbol from pieces. In particular, the characters
U+239B LEFT PARENTHESIS UPPER HOOK through
U+23B3 SUMMATION BOTTOM represent a set of glyph pieces
for building up large versions of the fences , ,
, , , and ,
and of the large operators and . These brace and
operator pieces are compatibility characters. They should not be used in stored mathematical text,
but are often used in the data stream created by display and print drivers.
Table 6 shows which pieces are intended to be used together to create specific symbols.
Table 6. Use of Symbol Pieces
| 2-row | 3-row | 5-row | |
|---|---|---|---|
| Summation | 23B2, 23B3 | ||
| Integral | 2320, 2321 | 2320, 23AE, 2321 | 2320, 3×23AE, 2321 |
| Left Parenthesis | 239B, 239D | 239B, 239C, 239D | 239B, 3×239C, 239D |
| Right Parenthesis | 239E, 23A0 | 239E, 239F, 23A0 | 239E, 3×239F, 23A0 |
| Left Bracket | 23A1, 23A3 | 23A1, 23A2, 23A3 | 23A1, 3×23A2, 23A3 |
| Right Bracket | 23A4, 23A6 | 23A4, 23A5, 23A6 | 23A4, 3×23A5, 23A6 |
| Left Brace | 23B0, 23B1 | 23A7, 23A8, 23A9 | 23A7, 23AA, 23A8, 23AA, 23A9 |
| Right Brace | 23B1, 23B0 | 23AB, 23AC, 23AD | 23AB, 23AA, 23AC, 23AA, 23AD |
For example, an instance of U+239B can be positioned relative to instances of U+239C and U+239D to form an extra-tall (three or more line) flattened left parenthesis. The center sections are meant to be used only with the top and bottom pieces encoded adjacent to them because the segments are usually graphically constructed within the fonts so that they match perfectly when positioned at the same x coordinates. An example is Here the two outermost parentheses are made of up multiple symbol pieces; the others are glyph variants of various heights.
In mathematics some operators or punctuation are often implied, but not displayed. This poses few problems to the human reader, as the meaning is usually clear from context. However, machine interpretation of mathematical expressions may need the intent be made more explicit. To support this without altering the appearance of the equation when displayed, the Unicode Standard provides several invisible operators that can be used to unambiguously denote the intent whenever an operator is implied, or more importantly when more than one operator could be implied. Use of invisible operators is optional and is not required or intended for interchange with math-unaware programs.
Invisible Separator.
U+2063 INVISIBLE SEPARATOR or invisible
comma is intended for use in index expressions and other mathematical notation where two adjacent
variables form a list and are not implicitly multiplied. In mathematical notation, commas are not
always explicitly present, but need to be indicated for symbolic calculation software to help it
disambiguate a sequence from a multiplication. For example, the double
subscript in the variable
means
— that is, the
and
are separate indices and not a single variable with the name
or even the product of
and
Accordingly, to represent the implied list separation in the subscript
one can insert a non-displaying invisible separator between the
and
.
In addition, use of the invisible comma might hint to a math layout program to set a small space
between the variables if they are not in subscripts or superscripts.
Invisible Multiplication.
Similarly, an expression like
implies that the mass multiplies the square of the speed
. To represent the implied multiplication in
unambiguously, one can insert a non-displaying U+2062 INVISIBLE TIMES between the and the .
Another example is the expression
,
which means the same as
,
where is used here to represent multiplication, not the cross
product. Note that the spacing between characters may also depend on whether the adjacent
variables are part of a list or are to be concatenated, that is, multiplied.
Invisible Function Application.
U+2061 FUNCTION APPLICATION is used for an implied
function dependence as in
.
To indicate that this is the function of the quantity
and not the expression
,
one can insert the non-displaying function application symbol between the
and the left parenthesis.
Invisible Plus.
The final member of this set of invisible operators that denote the implied intent of juxtaposition
in uses where it is not possible to rely on a human reader to disambiguate is the
U+2064 INVISIBLE PLUS OPERATOR character to unambiguously
represent expressions like , which occur frequently in school or engineering
texts. Specifically, to ensure that means
plus
, one inserts the invisible plus symbol between
the and the . Not having an operator at all would imply
multiplication as in the example
where the represents a factor multiplying the fraction
.
Unicode has a number of solidi and reverse solidi, which have various mathematical semantics. The
most well-known solidus is U+002F SOLIDUS (slash,
virgule), which appears on most keyboards. It is used to separate alternatives, to separate fields in
URLs (or more generally, in IRIs), and in mathematical contexts to denote division, although
U+2215 DIVISION SLASH is the official division operator.
The most well-known reverse solidus is U+005C REVERSE SOLIDUS (backslash), which is used in a variety of ways, notably in file path names,
TEX macro names, and as a surrogate for mathematical operators such as U+2216 SET MINUS. Table 7 displays
various Unicode solidi. In addition, there are small form and full-width variants (U+FE68
, U+FF0F , U+FF3C )
and the empty-set symbols (U+29B0 .. U+29B4 ).
Table 7. Solidi and Reverse Solidi
| 002F | SOLIDUS = slash, virgule |
005C | REVERSE SOLIDUS = backslash |
||
| 0338 | COMBINING LONG SOLIDUS OVERLAY | 20E5 | COMBINING REVERSE SOLIDUS OVERLAY | ||
| 0337 | COMBINING SHORT SOLIDUS OVERLAY | ||||
| 2044 | FRACTION SLASH for composing arbitrary fractions |
29F5 | REVERSE SOLIDUS OPERATOR | ||
| 2215 | DIVISION SLASH generic division operator |
2216 | SET MINUS | ||
| 233F | APL FUNCTIONAL SYMBOL SLASH BAR | 2340 | APL FUNCTIONAL SYMBOL BACKSLASH BAR | ||
| 2341 | APL FUNCTIONAL SYMBOL QUAD SLASH | 2342 | APL FUNCTIONAL SYMBOL QUAD BACKSLASH | ||
| 2298 | CIRCLED DIVISION SLASH | 29B8 | CIRCLED REVERSE SOLIDUS | ||
| 2571 | BOX DRAWINGS LIGHT DIAGONAL UPPER RIGHT TO LOWER LEFT might not have 45° slope not used in math |
2572 | BOX DRAWINGS LIGHT DIAGONAL UPPER LEFT TO LOWER RIGHT might not have 135° slope not used in math |
||
| 27CB | MATHEMATICAL RISING DIAGONAL = \diagup
must have 45° slope |
27CD | MATHEMATICAL FALLING DIAGONAL = \diagdown
must have 135° slope |
||
| 29C4 | SQUARED RISING DIAGONAL SLASH | 29C5 | SQUARED FALLING DIAGONAL SLASH | ||
| 29F6 | SOLIDUS WITH OVERBAR | 29F7 | REVERSE SOLIDUS WITH HORIZONTAL BAR | ||
| 29F8 | BIG SOLIDUS = \xsol
|
29F9 | BIG REVERSE SOLIDUS = z notation schema hiding = \xbsol
|
U+2044 FRACTION SLASH is typically used to build up
simple skewed fractions in running text. It applies to immediately adjacent sequences of decimal
digits, that is, to spans of characters with the General Category property value Nd. For example,
1⁄2 should be displayed as ½. In ordinary plain text, any character other than a digit delimits
the numerator or denominator. So 5 1⁄2 should be displayed as 5½ because a space follows the 5.
In general mathematical use, a more versatile method for layout of fractions is needed (see, for
example, Section 2.1, Fractions of [UTN28]), however parsers of mathematical
texts should be prepared to handle fraction slash when it is received from other sources.
U+27CB MATHEMATICAL RISING DIAGONAL and U+27CD MATHEMATICAL FALLING DIAGONAL are mathematical symbols
for specific uses, to be distinguished from the more widely used solidi and reverse solidi operators as
well as from nonmathematical diagonals. U+27CB corresponds to the LATEX entity
\diagup and U+27CD to \diagdown.
Their glyphs are invariably drawn with 45° and 135° slopes, respectively, instead of the more upright
slants typical for the solidi operators. The diagonals are also to be distinguished from the two box
drawing characters U+2571 and U+2572. While in some fonts those characters may be drawn with 45° and
135° slopes, respectively, they are not intended to be used as mathematical symbols. One usage
recorded for U+27CB and U+27CD is in the notation for spaces of double cosets.
All remaining Unicode characters may appear in mathematical expressions, typically in spelled-out
names for variables in fractions or in simple formulae, but they most commonly appear in ordinary
text. An English example is the equation
distance = rate × time
, which uses ordinary ASCII
letters to aid in recognizing sequences of letters as words instead of products of individual
symbols. Such usage corresponds to identifiers as discussed elsewhere in this report.
The period (U+002E FULL STOP) and U+002C COMMA are widely used as numerical punctuation, however, their meaning
depends on local conventions. See [CLDR]. For Arabic, U+066B ARABIC DECIMAL SEPARATOR or U+002C COMMA are used. Note that U+0660 ARABIC-INDIC DIGIT ZERO is easily confused with a period, which
leads to the fact that it is often spelled out.
Many negated forms, particularly of relations, can be encoded by using the base symbol, together with a combining overlay. Occasionally, both a vertical and a slanted negation are used; which one is often a matter of style. Sometimes the negation is indicated for only part of a symbol. In these cases, the negated relations are encoded directly, and variants can be accessed via the variation selector method described in the next section.
Table 8 lists the currently encoded negated mathematical relations
for which a variant can be realized via composition, by using U+20D2 COMBINING LONG VERTICAL LINE OVERLAY together with a base character. In
the table, the part of the description in small caps is the character name of
the corresponding standard character; the part in lowercase indicates the variation in appearance.
Table 8. Negated Relations Using Vertical Line Overlay
| Std Symbol | Alternate Symbol | Description of alternate symbol | |||
|---|---|---|---|---|---|
| 2209 | 2208,20D2 | not an element of with vertical stroke | |||
| 220C | 220B,20D2 | does not contain as member with vertical stroke | |||
| 2241 | 223C,20D2 | not tilde with vertical stroke | |||
| 2244 | 2243,20D2 | not asymptotically equal to with vertical stroke | |||
| 2247 | 2245,20D2 | neither approximately nor actually equal to with vertical stroke | |||
| 2249 | 2248,20D2 | not almost equal to with vertical stroke | |||
| 2260 | 003D,20D2 | not equal to with vertical stroke | |||
| 2262 | 2261,20D2 | not identical to with vertical stroke | |||
| 226D | 224D,20D2 | not equivalent to with vertical stroke | |||
| 226E | 003C,20D2 | not less-than with vertical stroke | |||
| 226F | 003E,20D2 | not greater-than with vertical stroke | |||
| 2270 | 2264,20D2 | neither less-than nor equal to with vertical stroke | |||
| 2271 | 2265,20D2 | neither greater-than nor equal to with vertical stroke | |||
| 2278 | 2276,20D2 | neither less-than nor greater-than with vertical stroke* | |||
| 2279 | 2277,20D2 | neither greater-than nor less-than with vertical stroke* | |||
| 2280 | 227A,20D2 | does not precede with vertical stroke | |||
| 2281 | 227B,20D2 | does not succeed with vertical stroke | |||
| 2284 | 2282,20D2 | not a subset of with vertical stroke | |||
| 2285 | 2283,20D2 | not a superset of with vertical stroke | |||
| 2288 | 2286,20D2 | neither a subset of nor equal to with vertical stroke | |||
| 2289 | 2287,20D2 | neither a superset of nor equal to with vertical stroke | |||
| 22E0 | 227C,20D2 | does not precede or equal with vertical stroke | |||
| 22E1 | 227D,20D2 | does not succeed or equal with vertical stroke | |||
* The representative glyphs shown in the code charts [Charts] were revised in [Unicode4.0] to show the forms with
slanted overlay — this matches their existing decomposition using U+0338 COMBINING LONG SOLIDUS OVERLAY (see Section 2.3.2 Representative Glyphs for U+2278 and U+2279 for more information).
Note that the use of a base character together with the slanted negation expressed by U+0338 COMBINING LONG SOLIDUS OVERLAY is equivalent to the
use of the precomposed negation (see also the discussion in Section 2.6 Accented Characters). For those symbols for which only a partial vertical stroke is
used, use of U+20D2 would not give the intended result; U+FE00 VARIATION SELECTOR-1 is used instead, as described in Section 2.18 Variation Selector.
Table 9 lists some of the negated forms of mathematical relations
that can only be encoded by using either U+0338 COMBINING LONG SOLIDUS OVERLAY or U+20D2 COMBINING LONG VERTICAL LINE OVERLAY. (For issues with using U+0338 in MathML, see
Section 3.2.7 Combining Marks. Depending on the overlay used, the negation has
a diagonal or vertical stroke. The part of the description that is in small
caps reflects the Unicode character name of the non-negated symbol. Because these are not
glyph variants of existing characters, the word “negated” is used instead of “NOT” as in the list
above, to indicate that the negation is expressed by the combining character sequence, and not
inherent in the character.
Table 9. Using Vertical Line or Solidus Overlay
| Glyph / Sequence | Glyph / Sequence | Description | |||
|---|---|---|---|---|---|
| 220A,0338 | 220A,20D2 | negated small element of | |||
| 220D,0338 | 220D,20D2 | negated small contains as member | |||
| 2242,0338 | 2242,20D2 | negated minus tilde | |||
| 2263,0338 | 2263,20D2 | negated strictly equivalent to | |||
| 2266,0338 | 2266,20D2 | negated less-than over equal to | |||
| 2267,0338 | 2267,20D2 | negated greater-than over equal to | |||
| 22F7,0338 | 22F7,20D2 | negated element of with overbar | |||
| 22FE,0338 | 22FE,20D2 | negated small contains with overbar | |||
| 2A6C,0338 | 2A6C,20D2 | negated similar minus similar | |||
| 2A70,0338 | 2A70,20D2 | negated approximately equal or equal to | |||
| 2A7D,0338 | 2A7D,20D2 | negated less-than or slanted equal to | |||
| 2A7E,0338 | 2A7E,20D2 | negated greater-than or slanted equal to | |||
| 2A95,0338 | 2A95,20D2 | negated slanted equal to or less-than | |||
| 2A96,0338 | 2A96,20D2 | negated slanted equal to or greater-than | |||
| 2A99,0338 | 2A99,20D2 | negated double-line equal to or less-than | |||
| 2A9A,0338 | 2A9A,20D2 | negated double-line equal to or greater-than | |||
| 2AC5,0338 | 2AC5,20D2 | negated subset of above equals sign | |||
| 2AC6,0338 | 2AC6,20D2 | negated superset of above equals sign | |||
In some cases, as seen in the two preceding tables, simply using the generic glyph for the
vertical overlay will not give the correct appearance. U+2266 LESS-THAN OVER EQUAL TO and U+2A99 DOUBLE-LINE EQUAL TO OR LESS-THAN are examples of characters that may require a taller stroke. Similarly,
the generic position of the solidus overlay as shown for U+2AC6 SUPERSET OF ABOVE EQUALS SIGN above is not ideal.
The variation selector VS1 is used to represent well-defined variants of particular math symbols. The
variations include: different slope of the cancellation element in some negated symbols, changed
orientation of an equating or tilde operator element, and some well-defined different shapes. These
mathematical variants are all produced with the addition of U+FE00 VARIATION SELECTOR-1 (VS1) to mathematical operator base characters.
To select one of the predefined variations, follow the base character with the variation selector.
Table 10 lists only the currently defined combinations that are of interest for mathematics. In the table, the part of the description in small caps is the character name of the corresponding standard character; the part in lowercase indicates the variation in appearance. The table of normative standardized variants [StdVar] in the Unicode Character Database lists the full set of all valid and recognized combinations. Their representative glyphs are shown in the code charts [Charts]. All combinations not listed there are unspecified and are reserved for future standardization; no conformant process may interpret them as standardized variants. For more information, see Section 23.4, Variation Selectors, in [Unicode].
Table 10. Variants of Mathematical Symbols using VS1
| Sequence | Description |
|---|---|
| 0030 + VS1 | digit zero – short diagonal stroke form |
| 2205 + VS1 | empty set – zero with long diagonal stroke overlay form |
| 2229 + VS1 | intersection – with serifs |
| 222A + VS1 | union – with serifs |
| 2268 + VS1 | less-than but not equal to – with vertical stroke |
| 2269 + VS1 | greater-than but not equal to – with vertical stroke |
| 2272 + VS1 | less-than or equivalent to – following the slant of the lower leg |
| 2273 + VS1 | greater-than or equivalent to – following the slant of the lower leg |
| 228A + VS1 | subset of with not equal to – with stroke through bottom members |
| 228B + VS1 | superset of with not equal to – with stroke through bottom members |
| 2293 + VS1 | square cap – with serifs |
| 2294 + VS1 | square cup – with serifs |
| 2295 + VS1 | circled plus – with white rim |
| 2297 + VS1 | circled times – with white rim |
| 229C + VS1 | circled equals – with equal sign touching the circle |
| 22DA + VS1 | less-than equal to or greater-than – with slanted equal |
| 22DB + VS1 | greater-than equal to or less-than – with slanted equal |
| 29B7 + VS1 | circled parallel – with parallel lines touching the circle |
| 2A3C + VS1 | interior product – tall variant with narrow foot |
| 2A3D + VS1 | righthand interior product – tall variant with narrow foot |
| 2A9D + VS1 | similar or less-than – with similar following the slant of the upper leg |
| 2A9E + VS1 | similar or greater-than – with similar following the slant of the upper leg |
| 2AAC + VS1 | smaller than or equal to – with slanted equal |
| 2AAD + VS1 | larger than or equal to – with slanted equal |
| 2ACB + VS1 | subset of above not equal to – with stroke through bottom members |
| 2ACC + VS1 | superset of above not equal to – with stroke through bottom members |
| FF10 + VS1 | fullwidth digit zero – short diagonal stroke form |
| 1DB10 + VS1 | cartesian equals sign – with descender |
| 223D + VS1 | reversed tilde – using lazy s |
| 2243 + VS1 | asymptotically equal to – using lazy s |
| 22CD + VS1 | reversed tilde equals – using lazy s |
| 2242 + VS1 | minus tilde – using lazy s |
| 2248 + VS1 | almost equal to – using lazy s |
| 2A6C + VS1 | similar minus similar – using lazy s |
| 22DC + VS1 | equal to or less-than – with horizontal equal |
| 22DD + VS1 | equal to or greater-than – with horizontal equal |
Using a variation selector allows users and font designers to make a distinction between two alternate glyph shapes both of which are ordinarily acceptable glyphs for generic, non-distinguishing usage of the standalone character code. This situation is somewhat analogous to the variants of Greek letterforms, which are not distinguished when used in text, but must be distinguished when used as symbols. See Section 2.3.1 Representative Glyphs for Greek Phi. However, unlike the Greek symbols that have distinct character codes, the Unicode Standard considers the distinctions expressed via the variation selector as optional. Processes or fonts that cannot support a variation selector should yield acceptable results by ignoring it.
A variation selector only selects a different appearance of an already encoded character. It is not intended as a general code extension mechanism. If the two shapes can be shown to have consistently different usage and semantics in some context because of a change over time or because of better evidence about how each shape is actually used in mathematical notation, this constitutes support for adding another character so that the distinction in meaning can be expressed by a difference in character code.
Mathematicians are inventive people who continue to invent new symbols to express their concepts. Novel symbols must become established before they can be standardized. Therefore, one needs a way to handle these novel symbols in the interim.
The Private Use Areas (U+E000..U+F8FF, U+F0000..U+FFFFD, and U+100000..U+10FFFD) can be used for such nonstandard symbols. However, that can be a tricky business, because the Private Use Area (PUA) is used for many purposes. Hence, when using the PUA, it is a good idea to have higher-level backup to define what kind of characters are involved. If they are used as math symbols, it would be helpful to assign them a math attribute that is maintained in a rich-text layer parallel to the plain text.
Markup languages also may have other ways of using arbitrary glyphs as ‘pseudo-characters’; for instance, [MathML] has an <mglyph> element.
Unicode assigns a number of mathematical character properties to aid in the default interpretation and rendering of mathematical characters. Such properties include the classification of characters into operator, digit, delimiter, and variable. These properties may be overridden, or explicitly specified in some environments, such as [MathML], which uses specific tags to indicate how Unicode characters are used, such as <mo> for operator, <mn> for one or more digits comprising a number, and <mi> for identifier. [TEX] is a higher-level composition system that uses implicit character semantics. In the following, these properties are described in greater detail.
Many Unicode characters occur nearly always as part of mathematical expressions and are given the generic Math property [Math]. These include the math operators in the ranges U+2200..U+22FF and U+29B0..U+2AFF, the math combining marks U+20D0..U+20EF, and the mathematical alphanumeric characters (some of the Letterlike Symbols block at U+2100..U+214F, together with the Mathematical Alphanumeric Symbol block U+1D400..U+1D7FF). Other characters may occur in mathematical usage depending on context. The Math property is useful in heuristics that seek to identify mathematical expressions in plain text.
For more information about character properties, see Unicode Technical Report #23, "The Unicode Character Property Model" [UTR23].
Each character in the Unicode Standard is given a General Category. This is one of a set of values that represent a primary feature or function of a character. Characters that are primarily used as mathematical symbols and operators are given the General Category (gc) value of Symbol_Math (Sm).
However, many characters commonly or exclusively used in mathematics are classified by their function as delimiting punctuation, rather than as math symbols. This particularly affects many of the math delimiters. The Math property, which is designed to be applied to all characters used primarily or exclusively with mathematical notation, is therefore a superset of the characters with gc = Sm. The difference between the sets of characters that have the math property and those for which gc = Sm is given by the set of characters that have the Other_Math property.
Strongly mathematical characters are characters that are used primarily or exclusively in mathematical notation. This includes all characters with the Math property in Unicode.
The concept of mathematical use is deliberately kept broad; therefore the Math property is also
given to characters that are used as operators, but are not part of standard mathematical
notation, such as U+2052 ⁒ COMMERCIAL MINUS. Further, all
characters that are compatibility equivalents of strongly mathematical characters have been given
the Math Property.
Despite their classification as strongly mathematical characters, many characters also occur in non-mathematical texts as well. However, all letters, as well as the delimiters in the ASCII range, such as parentheses and brackets, are so common in non-mathematical use that they are considered weakly mathematical characters. For details on the assignment of the math property see Unicode Standard Annex #44, "Unicode Character Database" [UAX44].
Note: The Math property in Unicode 4.0 and earlier did include these ASCII characters, and did not include many characters more specifically used for mathematics. The Math property in [Unicode4.0.1] and later versions has been redesigned to be a superset of strongly mathematical characters as defined here.
Weakly mathematical characters commonly appear in mathematical
expressions, but also appear in ordinary text. They include the ASCII letters
and punctuation, as well as the arrows, and many of the geometric and technical
shapes. The ASCII hyphen minus (U+002D ) is a weakly mathematical character
that may be used for the subtraction operator, but U+2212 MINUS SIGN is preferred for this purpose and looks better.
Geometric shapes are frequently used as mathematical operators, but have other uses as well.
Weakly mathematical characters include the characters listed in Table 11. However this list is not comprehensive. It does not list the Miscellaneous Technical, or the Miscellaneous Symbols blocks, even though they contain characters such as the die faces or card suits that are occasionally used for a specific purpose in mathematical context. On the other hand, Table 11 includes characters that some authorities would not consider proper for mathematical notation.
Table 11. Weakly Mathematical Characters
| Code | Description |
|---|---|
| 0021 | exclamation mark (factorial) |
| 0028..0029 | ASCII Parentheses |
| 002A | asterisk |
| 002C | comma |
| 002F | solidus |
| 002D | hyphen-minus |
| 002E | full stop (period) |
| 0030..0039 | Digits |
| 0041..005A | Uppercase Latin letters |
| 0061..007A | Lowercase Latin letters |
| 006E | circumflex accent |
| 005B,005D | Square brackets |
| 005C | reverse solidus (backslash) |
| 007B,007D | Curly brackets |
| 007E | tilde |
| 3010..3011 | CJK brackets unified with math use |
| 3014..3019 | CJK brackets unified with math use |
Additionally:
The characters in Table 12 are compatibility variants of weakly mathematical characters. Since the list of characters that have the math property in Unicode includes compatibility variants, the characters in this table should also be considered weakly mathematical characters.
Table 12. Weakly Mathematical Compatibility Characters
| Code | Description |
|---|---|
| FE35..FE38 | Vertical parentheses and brackets |
| FE47..FE48 | Vertical parentheses and brackets |
| FE59..FE5C | CJK small forms of parentheses and brackets |
| FF0D | fullwidth hyphen-minus |
| FF0F | fullwidth solidus (slash) |
| FF08..FF09 | Fullwidth parentheses |
| FF4E | fullwidth circumflex accent |
| FF3B,FF3D | Fullwidth square brackets |
| FF3C | fullwidth reverse solidus (backslash) |
| FF5B,FF5D | Fullwidth curly brackets |
| FF5C | Fullwidth vertical bar |
| FF5E | fullwidth tilde |
| FFE9..FFEC | Halfwidth arrows |
The math class property described here indicates the common use of each character. Some characters are routinely used in different contexts, requiring different spacing, Such differences need to be inferred from additional markup, or from the context. Such mechanisms are not described in this document.
Notable examples are:
U+0021 EXCLAMATION MARK has been assigned class C (closing) corresponding to the [TEX] class \mathclose, reflecting its use as
a suffix operator denoting factorial. In other contexts it may be used as an ordinary symbol
corresponding to class N (\mathord).
U+2020 DAGGER and U+2021 DOUBLE DAGGER are given class R (Relation) but in some contexts
will be used as ordinary symbols corresponding to Math class N.
Any of the other Unicode characters may occur in mathematical texts, though, when they do, it is more common to find them as part of the descriptive text than as part of the mathematical expressions.
Math characters fall into a number of subcategories, such as operators, digits, delimiters, and identifiers (constants and variables). This section discusses some of the typographical characteristics of these subcategories. These characteristics and classifications are useful in the absence of overriding information. For example, there is at least one document that uses the letter P, in upright roman typestyle, as a relational operator.
In general, math italic Latin characters are used to represent single-character Latin variables. In contrast, mathematical function names like , , , , etc., are represented by upright and usually serifed text to distinguish them from products of variables. Such names should then not use the math alphanumeric characters. The upright uppercase Greek letters are favored over the math italic ones. Products of italicized variables have slightly wider spacing than the letters in italicized words in ordinary text.
The five double-struck, italic characters, upper-case differential
U+2145 DOUBLE-STRUCK ITALIC CAPITAL D), differential
d (U+2146 DOUBLE-STRUCK ITALIC SMALL D), exponential
(U+2147 DOUBLE-STRUCK ITALIC SMALL E), and imaginary
units (U+2148 DOUBLE-STRUCK ITALIC SMALL I,
U+2149 DOUBLE-STRUCK ITALIC SMALL J) are useful for
representing these mathematical entities unambiguously. Word processors can offer options to
display them as double-struck italic as shown here or as upright or italic according to local
convention. Common American mathematical practice displays these entities as math-italic while
common European practice displays them upright.
Operators fall into one or more categories. Table 13 shows two sets of mutually independent categories:
Table 13. Some Operator Categories
| Category | Notes | Category | Notes |
|---|---|---|---|
| binary | some spacing around binary operators | arithmetic | arithmetic includes binary and unary operators |
| unary | closer to modified character than binary operators | logical | unary not and binary and, or, exclusive or in a host of guises |
| n-ary | often called “large” operators, take limits | set-theoretic | inclusion, exclusion, in a variety of guises |
| relational | binary operators like less/greater than in many forms |
As in arithmetic, operators have precedence, which streamlines the interpretation of operands and reduces the notational complexity of expressions. Operator precedence is commonly used for this purpose in computer programming languages, calculus, and algebra. Assigning consistent default precedence to the operators allows software to automate the transition from data input (or plain text) to fully marked up forms of mathematical data such as TEX or MathML.
For example, in arithmetic, , not . Similarly, the plain-text expression means not . As in arithmetic, precedence can be overruled by explicit delimitation, so gives the latter.
Large Operators include n-ary operators like summation and integration. They may expand in size to fit their associated expressions. They generally also take limits. The placement of the limits on an operator is different when it is used in-line compared to its use in displayed formulae. For example when the expression is laid out in-line, the limits are placed at the top and bottom right hand side. However, when displayed out-of-line, as in the limits are normally placed above and below. The Unicode Standard does not specify any particular layout for limit expressions. Instead, it assumes that implementations follow the accepted typographical practices for mathematical layout.
European tradition prefers a more upright shape for the integrals. To implement this style preference an appropriate font must be used, as there is only a single character code for each integral.
Digits include 0-9 in various styles. All digits of a particular style have the same width.
Delimiters include punctuation, opening/closing delimiters such as parentheses and brackets, braces, and fences. Opening and closing delimiters and fences may expand in size to fit their associated expressions. Some bracket expressions do not appear to be “logical” to readers unfamiliar with the notation, for example, . In right-to-left layout, delimiters are mirrored. See Section 4.2 Bidirectional Layout of Mathematical Text.
Fences are similar to opening and closing delimiters, but may be used alone or as both opening and closing as the vertical bars in the absolute value .
Combining marks are used with mathematical alphabetic characters (see Section 2.6 Accented Characters), instead of precomposed characters.
Use <U+0061, U+0308> for the second derivative of acceleration with respect to time, not
the precomposed letter U+00E4 LATIN SMALL LETTER A WITH DIAERESIS. In fact, one generally wants the math italic a (U+1D44E) for
rather than the ASCII a
(U+0065) and by design no precomposed math alphanumerics exist. On the other hand, precomposed characters
are used for operators whenever they exist. Combining slash (solidus) or vertical overlays can be
used to indicate negation for operators that do not have precomposed negated forms.
Where both long and short combining marks exist, use the long, for example, use U+0338, not
U+0337 COMBINING SHORT OVERLAY and use U+20D2, not
U+20D3 COMBINING SHORT VERTICAL LINE OVERLAY. The
actual shape or position of a combining mark is a typesetting problem and not specified in plain
text. When using combining marks, the composite characters have the same typesetting class as the
base character.
In MathML combining marks are used to select math accents, which may be applied to single
variables or entire expressions. If possible, do not use combining marks to denote math accents,
but use the spacing equivalent. For example, instead of U+0303 COMBINING TILDE use U+02DC SMALL TILDE,
which is a spacing character. The reason for that recommendation is that such combining marks
would start an element, and, in the source code, would therefore combine with the preceding
“”. While this ordinarily does not present problems for parsers, a
particularly challenging case is U+0338 COMBINING LONG SOLIDUS OVERLAY because it is part of a canonical decomposition of U+226F NOT GREATER-THAN.
A use of combining marks (and variation selectors) in MathML which does not risk unwanted
combination with the markup syntax is the use in a single text run in a token element such
as <mo>. For example U+2245 APPROXIMATELY EQUAL TO followed by U+20D2 COMBINING LONG VERTICAL LINE OVERLAY
<mo>≅⃒</mo>
displays as a negated operator: .
If Normalization Form C is applied to mathematical text, some accents or overlays used with BMP alphabetic characters may be composed with their base character, even though for mathematical text the decomposed forms would have been preferred. Parsers should allow for this. Normalization forms KC or KD remove the distinction between different mathematical alphabets. These forms cannot be used with mathematical texts. For more details on Normalization see Unicode Standard Annex #15, "Unicode Normalization Forms" [UAX15] and the discussion in Section 2.6 Accented Characters.
If combining accents follow syntax characters in a markup language, there may be several issues. A source editor might display the combining mark as if the syntax character was the intended base character. This is an issue where the syntax character precedes data, such as for the terminating > characters. This is usually not an issue in processing the data, as the parser can correctly separate the data from the syntax characters.
However, U+0338 COMBINING LONG SOLIDUS OVERLAY is a
combining diacritical mark that combines with U+003E GREATER-THAN SIGN under NFC (producing U+226F NOT GREATER-THAN). That means that NFC changes the encoding of the syntax character in this case.
On the other hand, the parser should probably not try to decompose any instances of the not
greater than operator. Therefore, use of U+0338 following a
markup tag does not work. In [MathML] 2.0 mathematical accents are tagged with
<mo> (operator) tag so the accents do not appear directly in mathematical text. But that causes
U+0338 ̸ to follow >. Because normalization changes U+003E > to U+226F ≯ if followed by U+0338 ̸ , an
alternative representation is needed. In this case it would be useful to allow use of the ASCII “/” as
an alias for 0338, for example,
<mover accent="true">
<mo>=</mo>
<mo>/</mo>
</mover>>
Because MathML
already uses spacing diacritics as aliases for the actual combining marks where they exist, this
extension would not be too disruptive. In plain HTML or XML the use of precomposed
U+226F does not give any problems, as long as data is not normalized
with NFD.
In a bidirectional context, the glyphs for mathematical operators and delimiters, other than arrows, are adjusted as described in Unicode Standard Annex #9, "Unicode Bidirectional Algorithm" [UAX9] (UBA). During display, the software must ensure that the rendered glyph is the correct one in the context of bidirectional texts. Note that neutral characters are generally assigned the directionality of the math zone, rather than being assigned by the UBA.
In a left-to-right context, LEFT PARENTHESIS will appear as “”, while in a right-to-left context it will appear with the mirrored glyph “”. In some mathematical usage, brackets may not be paired, or may be deliberately used in the reversed sense, such as . Mirroring assures that in a right-to-left environment, such specialized mathematical text continues to read and not .
If any of these expressions is displayed from right to left, then the mirrored glyphs are used.
Because of the difficulty in interpreting such expressions, authors of bidirectional text need to
make sure that readers can determine the desired directionality of the text from context. Mirroring
is not limited to paired characters: any character with the mirrored property will
need two mirrored glyphs-for example, U+222B INTEGRAL.
For some mathematical symbols, the “mirrored” form is not an exact mirror image. For example, the
direction of the circular arrow in U+2232 CLOCKWISE CONTOUR INTEGRAL reflects the direction of the integration along the contour, not the text
direction. In a right-to-left context, the integral sign would be mirrored, but the circular
arrow would retain its clockwise direction. Another example is the bidi-mirrored form of
U+221B CUBE ROOT, which consists of a mirrored radix
symbol with a non-mirrored digit '3'.
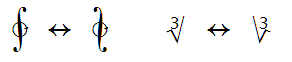
Figure 4. Examples of partially mirrored symbols
The list of mirrored characters appears in Unicode Standard Annex #44, "Unicode Character Database" [UAX44]. This normative property is not to be confused with the related Bidi Mirroring Glyph property, an informative property, which can assist in rendering a subset of mirrored characters in a right-to-left context by mapping to a paired character which happens to have the mirrored glyph. For more information, see BidiMirroring.txt in the Unicode Character Database.
For differences in conventions for laying out mathematical notations in Arabic, see [Lazrek].
Arrows.
In bidirectional layout, arrows are not automatically mirrored, because the direction of the
arrow could be relative to the text direction or relative to an absolute direction on the page or in
a diagram. Therefore, if text is copied from a left-to-right to a right-to-left context or vice
versa, the character code for the desired arrow direction in the new context must be used. For
example, it might be necessary to change U+21D2 RIGHTWARDS DOUBLE ARROW to U+21D0 LEFTWARDS DOUBLE ARROW to
maintain the semantics of implies in a right-to-left context.
See also Section 4.7, Bidi Mirrored in [Unicode] and “Mirroring of Paired Punctuation Semantics of Paired Punctuation” subsection in Section 6.2, General Punctuation, in [Unicode].
In view of the large number of characters used in mathematics, a brief and informal discussion of
possible approaches for input methods may be appropriate. Most keyboard layouts support the ASCII
letters, digits and some of the more common math symbols and delimiters, for example,
+ - / * [ ] ( ) { }. In addition to the limits on the number of symbols supported for
direct keyboard entry, sometimes the ASCII character only approximates the proper mathematical
character.
Post-entry Correction.
From a syntactical point of view, U+2212 MINUS SIGN is
certainly preferable to the U+002D HYPHEN-MINUS in the
ASCII range and U+2032 PRIME is preferable to U+0027 APOSTROPHE, but users may locate the ASCII characters
more easily. Similarly, it is easier to type ASCII letters than italic letters, but when used as
mathematical variables, such letters are traditionally italicized in print. Accordingly, a user might
want to make italic the default alphabet in a math context, reserving the right to overrule this
default when necessary. Other post-entry enhancements include automatic-ligature and left-right quote
substitutions, which can be done automatically by some word processors. Intelligent input algorithms
can dramatically simplify the entry of mathematical symbols. Among many examples, one can have
automatic substitutions like
/= → ,
<= → ,
>= → ,
~= → .
Input Method Editors. Many systems support interfaces for a user-selectable Input Method Editor (IME). While the technology of IMEs and the interfaces that support them were developed based on the needs of East Asian language input, the task of selecting one of over a thousand mathematical symbols at input time could be solved with a similar approach making use of the existing interfaces.
Math Keyboards. A special math shift facility for keyboard entry could bring up proper math symbols. The values chosen can be displayed on an on-screen keyboard. For example, the left Alt key could access the most common mathematical characters and Greek letters, the right Alt key could access italic characters plus a variety of arrows, and the right Ctrl key could access script characters and other mathematical symbols. On systems that support it, the numeric keypad offers locations for a variety of symbols, such as subscript and superscript digits using the left Alt key. Left Alt CapsLock could lock into the left-Alt symbol set, etc. This approach yields what one might call a “sticky” shift. Other possibilities involve the NumLock and ScrollLock keys in combinations with the left/right Ctrl/Alt keys. This approach rapidly approaches literally billions of combinations, that is, several orders of magnitude more than Unicode can handle!
Macros.
The autocorrect and keyboard macro features of some word processing systems provide other ways of
entering mathematical characters for people familiar with TEX. For example, typing
\alpha inserts if the appropriate autocorrect entry
is present. This approach is noticeably faster than using menus.
It is even faster if math autocomplete menus pop up as in they do in the
UnicodeMathML web app.
See unimath-symbols for a
list of LaTeX control words for almost all Unicode math symbols including most math alphanumerics.
See also XML_and_HTML_character_entities
Hexadecimal input. A handy hex-to-Unicode entry method works with some Microsoft text software (similar approaches are available on other systems) to insert Unicode characters, including math characters. Basically one types the hexadecimal code (in ASCII), making corrections as need be, and then types Alt+x. The hexadecimal code is replaced by the corresponding Unicode character. The Alt+x can be a toggle, that is, type it once to convert a hex code to a character and type it again to convert the character back to a hex code. If the hex code is preceded by one or more hexadecimal digits, one needs to “select” the code so that the preceding hexadecimal characters are not included in the code. The code can range up to the value 0x10FFFF, which is the highest character in the 17 planes of Unicode.
Pull-down Menus. Pull-down menus are a popular, but slow method for handling large character sets. A better approach is the symbol box, which is an array of symbols either chosen by the user or displaying the characters in a font. Symbols in symbol boxes can be dragged and dropped onto key combinations on an on-screen keyboard, or directly into applications. On-screen keyboards and symbol boxes are valuable for entry of mathematical expressions and of Unicode text in general.
It can be very useful to have typical mathematical symbols available in computer programs. To realize the full potential of supporting mathematical symbols as part of identifiers, a development environment should display the desired characters in both edit and debug windows. While a preprocessor could be used to translate MathML, for example, into C++, it would not be able to make the debug windows use the math-oriented characters because the language cannot handle the underlying Unicode characters. Java has made an important step in this direction by allowing Unicode characters to be used in identifiers. The mathematical alphanumeric symbols make this approach quite powerful for the user with relatively little effort for compilers.
There are three key advantages of using Unicode characters directly in computer program identifiers:
For more information on identifiers and syntax characters, see Unicode Standard Annex #31, "Unicode Identifiers and Syntax" [UAX31].
Mathematical expressions must be formatted using different rules than those applied to the surrounding text. When markup is used, the limits of the mathematical text are defined explicitly. In plain text it is possible to use a number of heuristics for identifying mathematical expressions. Once recognized, they can be treated appropriately, for example expressions input as plain text could be tagged with a rich-text math style. Such math style would connect in a straightforward way to appropriate MathML tags. Heuristics are not foolproof, but if they are applied as part of post-entry correction, the user could override cases that were tagged incorrectly. An algorithm for recognizing math is given in Section 5 of [UTN28].
Heuristics are based on the fact that a large set of characters in Unicode are primarily or exclusively used for mathematics; see Section 3.1.1 Strongly Mathematical Characters. Their presence potentially identifies their surrounding characters as math characters as well. For example, the fraction (U+2044) and ASCII slashes would tend to identify the characters immediately surrounding them as parts of mathematical expressions. The same applies to other mathematical characters and operators. On the other hand, many Unicode characters are not mathematical in nature and suggest that the characters immediately preceding or following them are not parts of mathematical expressions.
If Latin or Greek letter mathematical variables are already given in one of the math alphabets, they are considered parts of math expressions. If they are not, one can still use some recognition heuristics as well as the opportunity to italicize appropriate variables. Specifically, ASCII letter pairs surrounded by whitespace are often mathematical expressions, and should be converted to math italics. If a letter pair fails to appear in a list of common English and European two-letter words, it is treated as a mathematical expression and converted to italics.
Strings of characters containing no whitespace but containing one or more unambiguous mathematical characters are generally treated as mathematical expressions. Certain two-, three-, and four-letter words inside such expressions should not use italics. These include trigonometric function names like sin and cos, as well as ln, cosh, etc. Words or abbreviations that are often used as subscripts should not be italicized, even when they clearly appear inside mathematical expressions.
This section gives some additional, but still relatively straightforward examples of mathematical notation for the benefit of readers not familiar with it. There are two styles for presenting mathematical formula in text. Simple expressions are often presented in the so called inline format to conserve space and not break up the text. More complex formulae or those to which the author wants to call attention or that need to be numbered, are built-up and presented in the so-called display style. This use of the word display should not to be confused with the action of making text visible on display devices. The examples shown here are enlarged for clarity. For many other examples, see the Digital Library of Mathematical Functions.
The simple built-up fraction appears in inline text as ; similarly, the inline text could appear as when built-up. For the ratio
an inline format for which is (see [UTN28]).
The size of mathematical delimiters or operators may change on the size of the enclosed text. In an
equation such as
the size of the bracket scales with the size of the enclosed expression, in this case a fraction, and
the size of the integral could scale with the size of the integrand. The integral isn’t scaled here
because it is common practice to use one size for all larger integrals. This example also shows the
positioning of multiple sub- and superscripts as well as the positioning of limit expressions on the
integral. Punctuation following math in display is commonly placed on the local baseline or
centerline. The example
shows an increased space before the . In order to allow automatic
formatting of this, the special character code U+2146 DOUBLE-STRUCK ITALIC SMALL D can be used. In this instance, it would not
be rendered with an actual double struck glyph. The final example,
demonstrates regular text embedded in a mathematical formula.
The data file [Data] provides a classification of characters by primary their primary usage in mathematical notation. The classes used in this file are defined as follows:
Table 14. Classes of Mathematical Characters
| Class | Name | Comments |
|---|---|---|
| N | Normal | This includes all digits and symbols requiring only one form |
| A | Alphabetic | |
| B | Binary | |
| C | Closing | Usually paired with opening delimiter |
| D | Diacritic | |
| F | Fence | Unpaired delimiter or used for both opening and closing |
| G | Glyph_Part | Pieces for assembling large operators, brackets or arrows |
| O | Opening | Usually paired with closing delimiter |
| L | Large | N-ary or Large operator, often takes limits |
| P | Punctuation | |
| R | Relational | Includes arrows |
| S | Space | Space character |
| U | Unary | Unary operators |
| V | Vary | Operators that can be unary or binary |
| X | Special | Compatibility character |
The C, O, and F operators are stretchy. In addition, some binary operators, such as U+002F () are stretchy. The classes are also useful in determining extra spacing around operators (see Section 3.15 Section 3.16, Space Characters of [UTN28]). Character classification information will be updated when new characters are added to the standard, or to amend the classification of existing characters as necessary. The data file specifies the version of [Unicode] to which it has been updated. All characters that have the Math property are covered by this classification. Characters that are not classified here would most likely be used as ordinary symbols or letters (class N or A), if at all. However, no formal default Math_Class assignments have been made.
The mapping data file [Mapping] contains mappings to standard entity sets commonly used for SGML and MathML documents. Mapping data will be updated when new mapping information becomes available.
The use of the repertoire of mathematical characters in a mathematical context is not known to present special security considerations. However, many mathematical symbols can be confused with characters used in regular text. In particular, the mathematical alphanumeric symbols described in Section 2.2 Mathematical Alphabets can be confused with styled text. These characters are therefore excluded from use in security sensitive environments, such as domain names. For more information, see Unicode Technical Report #36, "Unicode Security Considerations" [UTR36].
| [CharProp] | Derived Core Properties https://www.unicode.org/Public/UCD/latest/ucd/DerivedCoreProperties.txt |
| [Charts] | The online code charts can be found at https://www.unicode.org/charts/. An index to character names with links to the corresponding chart is found at https://www.unicode.org/charts/charindex.html. |
| [CLDR] | Common Locale Data Repository https://www.unicode.org/cldr/ |
| [Data] | Classification of math characters by usage: https://www.unicode.org/Public/math/revision-16/MathClass-16.txt
For earlier versions of the data file see prior versions of this report. |
| [FAQ] | Unicode Frequently Asked Questions https://www.unicode.org/faq/ For answers to common questions on technical issues. |
| [Feedback] | To report errors or submit suggestions please use https://www.unicode.org/reporting.html. |
| [Glossary] | Unicode Glossary https://www.unicode.org/glossary/ For explanations of terminology used in this and other documents. |
| [ISO9573] | International Organization for Standardization. Information technology - SGML support facilities - Techniques for using SGML. Part 13: Public entity sets for mathematics and sciences. [Geneva]: 1991. (ISO/IEC TR9573-13:1991) |
| [ LATEX ] | Leslie Lamport, LATEX: A Document Preparation System, User's Guide & Reference Manual, 2nd edition, (Addison-Wesley, 1994; ISBN 1-201-52983-1) |
| [Mapping] | Information on mapping Unicode characters to existing ISO SGML entity sets (and some other data): http://www.unicode.org/Public/math/revision-16/MathClassEx-16.txt |
| [Math] | Math Property http://www.unicode.org/reports/tr44/#Math Defined in the Unicode Character Database |
| [MathML] | Mathematical Markup Language (MathML) Version 3.0 2nd Edition, D. Carlisle, P.D.F. Ion, and R.R. Miner, Editors, W3C Recommendation, April 10, 2014, http://www.w3.org/TR/2014/REC-MathML3-20140410/. Latest version available at http://www.w3.org/TR/MathML/. |
| [NISTGuide] | Ambler Thompson and Barry N. Taylor, (2008) Guide for the Use of the International System of Units (SI) NIST Special Publication 811, 2008 Edition (version 3.2). Available: http://physics.nist.gov/SP811 [2025, May 19]. National Institute of Standards and Technology, Gaithersburg, MD. |
| [OpenMath] |
OpenMath Consortium OpenMath Version 2.0, June 2004. http://www.openmath.org/standard/om20-2004-06-30/ |
| [Reports] | Unicode Technical Reports http://www.unicode.org/reports/ For information on the status and development process for technical reports, and for a list of technical reports. |
| [SI] | David B. Newell and Eite Tiesinga, Editors
(2019)
The International System of Units (SI)
NIST Special Publication 330, 2019 Edition. Available: https://www.nist.gov/pml/special-publication-330 [2025,
May 19]. National Institute of Standards and Technology, Gaithersburg, MD.
The metric system of weights and measures based on the meter, kilogram, second and ampere, Kelvin and candela. |
| [StdVar] | Formal list of Standardized Variants in the Unicode Character Database: http://www.unicode.org/Public/UCD/latest/ucd/StandardizedVariants.txt |
| [STIX] | STIX Project Home Page https://www.stixfonts.org/ |
| [ TEX ] | Donald E. Knuth, The TEXbook,
(Reading, Massachusetts: Addison-Wesley 1984) The TEXbook is the manual for Donald Knuth's TEX composition system. Appendix G describes the somewhat idiosyncratic mechanism used by TEX to accomplish the composition of mathematical notation; it is based on the principles laid out in [Chaundy], [Wick], and [Swanson], as well as on examination of a large number of published samples that demonstrated Knuth's style preferences. Donald E. Knuth, TEX, the Program, Volume B of Computers & Typesetting, (Reading, Massachusetts: Addison-Wesley 1986) See also http://www.ams.org/tex/publications.html |
| [UAX9] | Unicode Standard Annex #9, "Unicode Bidirectional Algorithm,"
edited by Manish Goregaokar and Robin Leroy (https://www.unicode.org/reports/tr9/) |
| [UAX11] | Unicode Standard Annex #11, "East Asian Width,"
edited by Ken Lunde (https://www.unicode.org/reports/tr11/) |
| [UAX15] | Unicode Standard Annex #15, "Unicode Normalization Forms,"
edited by Ken Whistler (https://www.unicode.org/reports/tr15/) |
| [UAX31] | Unicode Standard Annex #31, "Unicode Identifiers and Syntax,"
edited by Mark Davis and Robin Leroy (https://www.unicode.org/reports/tr31/) |
| [UAX44] | Unicode Standard Annex #44, "Unicode Character Database,"
edited by Ken Whistler (https://www.unicode.org/reports/tr44/) |
| [Unicode] | The latest version of the Unicode Standard can be found at https://www.unicode.org/versions/latest/. |
| [Unicode4.0] |
The Unicode Consortium. The Unicode Standard, Version 4.0.0, defined by: The Unicode Standard, Version 4.0 (Boston, MA, Addison-Wesley, 2003. ISBN 0-321-18578-1) https://www.unicode.org/versions/Unicode4.0.0/ |
| [Unicode4.0.1] |
The Unicode Consortium. The Unicode Standard, Version 4.0.1, defined by: The Unicode Standard, Version 4.0 (Boston, MA, Addison-Wesley, 2003. ISBN 0-321-18578-1) https://www.unicode.org/versions/Unicode4.0.1/ |
| [Unicode6.0] |
The Unicode Consortium. The Unicode Standard, Version 6.0.0, (Mountain View, CA: The Unicode Consortium, 2011. ISBN 978-1-936213-01-6)
https://www.unicode.org/versions/Unicode6.0.0/ |
| [Unicode6.1] |
The Unicode Consortium. The Unicode Standard, Version 6.1.0, (Mountain View, CA: The Unicode Consortium, 2012. ISBN 978-1-936213-02-3)
https://www.unicode.org/versions/Unicode6.1.0/ |
| [Unicode7.0] |
The Unicode Consortium. The Unicode Standard, Version 7.0.0, (Mountain View, CA: The Unicode Consortium, 2014. ISBN 978-1-936213-09-2)
https://www.unicode.org/versions/Unicode7.0.0/ |
| [UTN28] | Unicode Technical Note #28, "UnicodeMath, A Nearly Plain-Text Encoding of Mathematics,"
by Murray Sargent III (https://www.unicode.org/notes/tn28/) |
| [UTR23] | Unicode Technical Report #23, "The Unicode Character Property Model,"
edited by Asmus Freytag and Ken Whistler (https://www.unicode.org/reports/tr23/) |
| [UTR36] | Unicode Technical Report #36, "Unicode Security Considerations,"
edited by Mark Davis and Michel Suignard (https://www.unicode.org/reports/tr36/) |
| [Versions] | Versions of the Unicode Standard http://www.unicode.org/standard/versions This gives details on the precise contents of each version of the Unicode Standard, and how to cite them. |
| [XML] | Extensible Markup Language (XML) 1.0 (Fifth Edition), T. Bray, J. Paoli, M. Sperberg-McQueen, E. Maler, and F. Yergeau, Editors, W3C Recommendation, November 26, 2008, http://www.w3.org/TR/2008/REC-xml-20081126/. Latest version available at http://www.w3.org/TR/xml/. |
The following four books are entirely about the composition of mathematics:
| [Chaundy] | T.W. Chaundy, P.R. Barrett, and Charles Batey, The Printing of Mathematics, (London: Oxford University Press 1954, third impression, 1965) [out of print] |
| [Wick] | Karel Wick, Rules for Type-setting Mathematics, (Prague: Publishing House of the Czechoslovak Academy of Sciences 1965) [out of print] |
| [Swanson] | Ellen Swanson, Mathematics into Type, (Providence, RI: American Mathematical Society, 1971, revised 1979, updated 1999 by Arlene O'Sean and Antoinette Schleyer). The original edition is based on “traditional” composition (Monotype and “cold type”, that is Varityper and Selectric Composer); the 1979 edition adds material for computer composition, and the 1999 edition mostly assumes TEX or a comparably advanced system. |
| [Byrd] | Mathematics in Type, (Richmond, VA: The William Byrd Press 1954) [out of print] |
The following books contain material on mathematical composition, but it is not the principal topic covered:
| [Maple] | The Maple Press Company Style Book, (York, PA: 1931) (reprinted 1942) Contains sections on fractions; mathematical signs; simple equations; alignment of equations; braces, brackets and parentheses; integrals, sigmas and infinities; hyphens, dashes and minus signs; superiors and inferiors; ... [out of print] |
| [Manual] | A Manual of Style, Twelfth Edition, Revised, (Chicago: The University of Chicago Press 1969). A chapter “Mathematics in Type” was produced using the Penta (computer) system. The following more recent edition contains an expanded section on mathematics: Chicago Manual of Style, 15th edition, (University of Chicago Press, 2003) |
The following sources contain information on Arabic mathematical notation:
| [Lazrek] | Azzeddine Lazrek, Mustapha Eddahibi, Khalid Sami, and Bruce R. Miller, Arabic mathematical notation,
W3C Math Interest Group Note, 31 January 2006 http://www.w3.org/TR/arabic-math |
| [Benatia] | Mohamed Jamal Eddine Benatia, Azzeddine Lazrek, and Khalid Sami, Arabic mathematical symbols in Unicode,
Internationalization and Unicode Conference (IUC), IUC 27, Berlin,
Germany, April 6-8, 2005 https://web.archive.org/web/20240805163000/http://ucam.ac.ma/fssm/rydarab/doc/communic/unicodem.pdf |
Patrick Ion graciously reviewed the text of earlier versions of this report and suggested many improvements. Azzeddine Lazrek contributed information on Arabic mathematical notation. Rick McGowan redrew many of the figures. Laurențiu Iancu has made many important contributions to earlier verisons of the text as well as to the associated math data files.
This section indicates the changes introduced by each revision.
Revision 16
Revision 15
Revision 14
Revision 13
Revision 12
Revision 11
Revision 10 being a proposed update, only changes between revisions 9 and 11 are noted here.
Revision 9
Revision 8
Revision 7
Revision 6
Revision 5
Revision 4
Revision 3
Revision 2
Revision 1
© 2008–2025 Unicode, Inc. This publication is protected by copyright, and permission must be obtained from Unicode, Inc. prior to any reproduction, modification, or other use not permitted by the Terms of Use. Specifically, you may make copies of this publication and may annotate and translate it solely for personal or internal business purposes and not for public distribution, provided that any such permitted copies and modifications fully reproduce all copyright and other legal notices contained in the original. You may not make copies of or modifications to this publication for public distribution, or incorporate it in whole or in part into any product or publication without the express written permission of Unicode.
Use of all Unicode Products, including this publication, is governed by the Unicode Terms of Use. The authors, contributors, and publishers have taken care in the preparation of this publication, but make no express or implied representation or warranty of any kind and assume no responsibility or liability for errors or omissions or for consequential or incidental damages that may arise therefrom. This publication is provided “AS-IS” without charge as a convenience to users.
Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries.