| Version | 49 (draft) |
|---|---|
| Editors | Mark Davis, Peter Edberg, Rich Gillam, Alex Kolisnychenko, Mike McKenna and other CLDR committee members |
For the full header, summary, and status, see Part 1: Core.
This document describes parts of an XML format (vocabulary) for the exchange of structured locale data. This format is used in the Unicode Common Locale Data Repository.
This is a partial document, describing only those parts of the LDML that are relevant for person names (name structure, formats, sorting). For the other parts of the LDML see the main LDML document and the links above.
This is a draft document which may be updated, replaced, or superseded by other documents at any time. Publication does not imply endorsement by the Unicode Consortium. This is not a stable document; it is inappropriate to cite this document as other than a work in progress.
A Unicode Technical Standard (UTS) is an independent specification. Conformance to the Unicode Standard does not imply conformance to any UTS.
Please submit corrigenda and other comments with the CLDR bug reporting form [Bugs]. Related information that is useful in understanding this document is found in the References. For the latest version of the Unicode Standard see [Unicode]. For more information see About Unicode Technical Reports and the Specifications FAQ. Unicode Technical Reports are governed by the Unicode Terms of Use.
The LDML specification is divided into the following parts:
CLDR provides formatting for person names, such as John Smith or 宮崎駿. These use patterns to show how a name object (for example, from a database) should be formatted for a particular locale. Name data has fields for the parts of people’s names, such as a given field with a value of “Maria”, and a surname field value of “Schmidt”.
There is a wide variety in the way that people’s names appear in different languages.
This document provides the LDML specification for formatting of personal names, using data, structure, and examples.
The CLDR functionality is targeted at formatting names for typical usage on computers (e.g. contact names, automated greetings, etc.), rather than being designed for special circumstances or protocol, such addressing royalty. However, the structure may be enhanced in the future when it becomes clear that additional features are needed for some languages.
This addition to CLDR is based on review of current standards and practices that exist in LDAP, OECD, S42, hCard, HTML and various other international standards and commercial implementations.
Additions to those structures were made to accommodate known issues in large population groups, such as mononyms in Indonesia, patronymic and matronymic naming structure in Iceland and India, the need for a second surname in Spanish-speaking regions and the common case of chains of patronymic names in Arabic-speaking locales. The formatting patterns allow for specifying different “input parameters” to account for different contexts.
The following features are currently out of scope for Person Names formating:
Parsing of name strings into specific name parts such as given and given2. A name like "Mary Beth Estrella" could conceivably be any of the following.
| given | given2 | surname | surname2 |
|---|---|---|---|
| Mary | Beth | Estrella | |
| Mary Beth | Estrella | ||
| Mary | Beth Estrella | ||
| Mary | Beth | Estrella |
Parsing out the other components of a name in a string, such as surname prefixes (Tussenvoegsel in Dutch).
In addition to the settings in this document, it is recommended that implementations provide some additional features in their APIs to allow more control for clients, notably:
Logically, the model used for applying the CLDR data is the following:
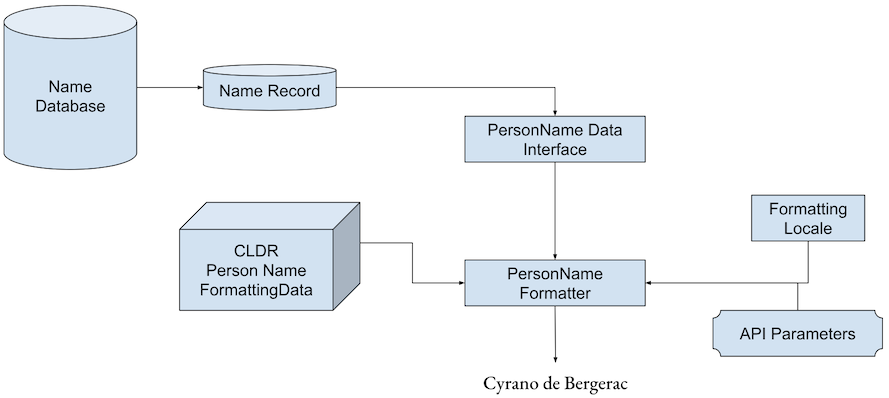
Conceptually, CLDR person name formatting depends on data supplied by a PersonName Data Interface. That could be a very thin interface that simply accesses a database record, or it could be a more sophisticated interface that can modify the raw data before presenting it to be formatted. For example, based on the formatting locale a PersonName data interface could transliterate names that are in another script, or supply equivalent titles in different languages.
The specification below will talk about a “PersonName object” as an entity that is logically accessed via such an interface. If multiple formatted names are needed, such as in different scripts or with alternate names, or pronunciations (eg kana), the presumption is that those are logically separate PersonName objects. See [Person Name Object].
The following summarizes the name data supplied via the PersonName Data Interface:
To format a name correctly, the correct context needs to be known. The context is composed of:
As an example, consider a person’s name that may contain:
title |
given |
given2 |
surname |
credentials |
|---|---|---|---|---|
| Robin | Finley | Wang | Ph.D. |
If the selected personName data has the following formatting pattern:
{title} {given} {given2-initial} {surname}, {credentials}
Then the output is:
Robin F. Wang, Ph.D.
The title field is empty, so both it and the space that follows it in the formatting pattern are omitted from the output, the given2 field is formatted as an initial, and a preceding comma is placed before the credentials.
Sections below specify the precise manner in which a pattern is selected, and how the pattern is modified for missing fields.
Person name formatting data is stored as LDML with schema defined as follows. Each element has a brief description of the usage, but the exact algorithms for using these elements are provided in Formatting Process.
<!ELEMENT personNames ( nameOrderLocales*, parameterDefault*, nativeSpaceReplacement*, foreignSpaceReplacement*, initialPattern*, personName*, sampleName* ) >
The LDML top-level <personNames> element contains information regarding the formatting of person names, and the formatting of person names in specific contexts for a specific locale.
The <personName> element contains the format patterns, or <namePattern> elements, for a specific context and is described in [namePattern Syntax]
The <namePattern> syntax is described in [Person Name Format Patterns].
<!ELEMENT personName ( namePattern+ ) >
<!ATTLIST personName order NMTOKEN #IMPLIED >
NMTOKEN is one of ( surnameFirst | givenFirst | sorting )<!ATTLIST personName length NMTOKEN #IMPLIED >
NMTOKEN is one of ( long | medium | short )<!ATTLIST personName usage NMTOKEN #IMPLIED >
NMTOKEN is one of ( addressing | referring | monogram )<!ATTLIST personName formality NMTOKEN #IMPLIED >
NMTOKEN is one of ( formal | informal )The <personName> element has attributes of order, length, usage, and formality, and contains one or more <namePattern> elements.
A missing attribute matches all valid values for that attribute. For example, if formality=... is missing, it is equivalent to multiple lines, one for each possible formality attribute.
<!ELEMENT namePattern ( #PCDATA ) >
A namePattern contains a list of PersonName fields enclosed in curly braces, separated by literals, such as:
<namePattern>{surname}, {given} {given2}</namePattern>
which produces output like “Smith, Robert James”. See [namePattern Syntax] for more details.
The <nameOrderLocales> element is optional, and contains information about selecting patterns based on the locale of a passed in PersonName object to determine the order of elements in a formatted name. For more information see [NameOrder]. It has a structure as follows:
<!ELEMENT nameOrderLocales `( #PCDATA )`>
<!ATTLIST nameOrderLocales order ( givenFirst | surnameFirst ) #REQUIRED >
#PCDATA is a space delimited list of one or more unicode_locale_ids. Normally each locale is limited to language, script, and region. The und locale ID may only occur once, either in surnameFirst or givenFirst, but not both, and matches all base locales not explicitly listed.An example from English may look like the following
<nameOrderLocales order="givenFirst">und en</nameOrderLocales>
<nameOrderLocales order="surnameFirst">ko vi yue zh</nameOrderLocales>
This would tell the formatting code, when handling person name data from an English locale, to use patterns with the givenFirst order attribute for all data except name data from Korean, Vietnamese, Cantonese, and Chinese locales, where the surnameFirst patterns should be used.
<!ELEMENT parameterDefault ( #PCDATA ) >
<!ATTLIST parameterDefault parameter (length | formality) #REQUIRED >
Many clients of the person-names functionality don’t really care about formal versus informal; they just want whatever the “normal” formality level is for the user’s language. The same goes for the default length.
This parameter provides that information, so that APIs can allow users to use default values for the formality and length. The exact form that this takes depends on the API conventions, of course.
The <foreignSpaceReplacement> element is used to specify how spaces should be handled when the name language is different from the formatting language. It is used in languages that don't normally require spaces between words. For example, Japanese and Chinese have the value of a middle dot (‘·’ U+00B7 MIDDLE DOT or ‘・’ U+30FB KATAKANA MIDDLE DOT), so that it is used between words in a foreign name; most other languages have the value of SPACE.
<!ELEMENT foreignSpaceReplacement ( #PCDATA ) >
<!ATTLIST foreignSpaceReplacement xml:space preserve #REQUIRED >
xml:space must be set to 'preserve' so that actual spaces in the pattern are preserved. See W3C XML White Space Handling.#PCDATA is the character sequence used to replace spaces when postprocessing a pattern.The <nativeSpaceReplacement> element is used to specify how spaces should be handled when the name language is the same as the formatting language. It is used in languages that don't normally require spaces between words, but may use spaces within names. For example, Japanese and Chinese have the value of an empty string between words in a native name; most other languages have the value of SPACE.
<!ELEMENT nativeSpaceReplacement ( #PCDATA ) >
<!ATTLIST nativeSpaceReplacement xml:space preserve #REQUIRED >
xml:space must be set to 'preserve' so that actual spaces in the pattern are preserved. See W3C XML White Space Handling.#PCDATA is the character sequence used to replace spaces when postprocessing a pattern.The <initialPattern> element is used to specify how to format initials of name parts.
initial is a pattern used to display a single initial in the locale, while initialSequence is a pattern used to “glue” together multiple initials for multiword fields, for example with the given name “Mary Beth” in English.
<!ELEMENT initialPattern ( #PCDATA ) >
<!ATTLIST initialPattern type ( initial | initialSequence) #REQUIRED >
The type="initial" is used to specify the pattern for how single initials are created, for example “Wolcott” => “W.” would have an entry of
<initialPattern type="initial">{0}.</initialPattern>
type="initialSequence” is used to specify how a series of initials should appear, for example “Wolcott Janus” => “W. J.”, with spaces between each initial, would have a specifier of
<initialPattern type="initialSequence">{0} {1}</initialPattern>
The information that is to be formatted logically consists of a data object containing a number of fields. This data object is a construct for the purpose of formatting, and doesn’t represent the source of the name data. That is, the original source may contain more information. The PersonName object is merely a logical ‘transport’ of information to formatting; it may in actuality consist of, for example, an API that fetches fields from a database.
Note that an application might have more than one set of name data for a given person, such as data for both a legal name and a nickname or preferred name. Or the source data may contain two whole sets of name data for a person from an Eastern Slavic region, one in Cyrillic characters and one in Latin characters. Or it might contain phonetic data for a name (commonly used in Japan). The additional application-specific information in person’s names is out of scope for the CLDR Person Name formatting data. Thus a calling application may produce more than one PersonName object to format depending on the purpose.
For illustration, the following is a sample PersonName object.
| Field | Value | Comment |
|---|---|---|
title |
“Dr.” | |
given |
“William” | |
given-informal |
“Bill” | example inclusion of "nickname" |
given2 |
“Torval” | |
surname |
“Brown” | |
nameLocale |
“und-US” | this is just for illustration |
preferredOrder |
“givenFirst” | values are givenFirst and surnameFirst |
A PersonName object is logically composed of the fields above plus other possible variations. See [Fields]. There must be at least one field present: either a given or surname field. Other fields are optional, and some of them can be constructed from other fields if necessary.
A modifier is supplied, -informal, which can be used to indicate which data element to choose when formatting informal cases which might include nicknames or preferred names. For more details, see section on [Modifiers] in namePattern Syntax below.
A person name pattern may have any of four attributes: order, length, usage, and formality. LDML specifies that all the values for these attributes are unique. For example, because length=long is valid, usage=long cannot also be valid. That allows the pattern labels to be simple, because the attribute names can be skipped. That is,
{order=givenFirst, length=long, usage=referring, formality=formal}
can be abbreviated without loss of information as:
givenFirst-long-referring-formal.
Each of these attributes are described below using sample PersonName objects as examples.
The order attribute is used for patterns with different orders of fields. The order=sorting patterns are chosen based on input parameters, while the choice between givenFirst and surnameFirst is based on features of the PersonName object to be formatted and the nameOrder element values.
| Parameter | Description |
|---|---|
givenFirst |
The given name precedes the surname. |
surnameFirst |
The surname precedes the given name. |
sorting |
Used to format names for a sorted list. example: “Brown, William” [medium, informal] |
For example, when the display language is Japanese, it is customary to use surnameFirst for names of people from Japan and Hungary, but use givenFirst for names of people from the United States and France. Although the English pattern for sorting is distinct from the other patterns (except for unusual names), that is not necessarily the case in other languages.
The length attribute specifies the relative length of a formatted name depending on context. For example, a long formal name in English might include title, given, given2, surname plus generation and credentials; whereas a short informal name may only be the given name.
Note that the formats may be the same for different lengths depending on the formality, usage, and cultural conventions for the locale. For example, medium and short may be the same for a particular context.
| Parameter | Description |
|---|---|
long |
A long length would usually include all parts needed for a legal name or identification.Example: usage="referring", formality="formal"“Mr. Robert John Smith, PhD” |
medium |
A medium length is between long and short.Example: usage="referring", formality="formal"“Robert Smith” |
short |
A short length uses a minimum set of names.Example: usage="referring", formality="formal"“Mr. Smith” |
The usage indicates if the formatted name is being used to address someone, refer to someone, or present their name in an abbreviated form.
The pattern for usage="referring" may be the same as the pattern for usage="addressing".
| Parameter | Description |
|---|---|
addressing |
Used when speaking “to” a person, or “vocative” case. This may also have an effect on the formality. example: “Welcome, Robert” |
referring |
Used when speaking “about” a person, or “nominative” case. example: “Robert Smith joined your group” |
monogram |
The monogram usage is for a specific abbreviated form for computer UI.Example: a monogram for Robert James Smith may be RS or RJS. |
Slavic languages provide a good example of addressing vs referring. An example uk-Cyrl PersonName object:
| Field | Value | Comment |
|---|---|---|
title |
“г-н” | “Mr.” |
given |
“Иван” | “Ivan” |
given2 |
“Петрович” | “Petrovich” |
surname |
“Васильев” | “Vasiliev” |
In Slavic languages, when addressing a person (with length="long"), it might be
// "Mr Ivan Petrovich Vasiliev"And when referring to a person, it might place the surname first.:
// "Vasiliev Ivan Petrovich"The monogram usage is for very short abbreviated names, such as might be found in online messaging text avatars or other annotations. Ideally, a monogram format should result in something that could fit in an em square. Some emoji provide examples of this: 🅰️ 🆎 🆘
When used with length, for many alphabetic locales a monogram would resolve to one, two, or three characters for short, medium, and long respectively. But that may vary depending on the usage in a locale.
The formality indicates the formality of usage. A name on a badge for an informal gathering may be much different from an award announcement at the Nobel Prize Ceremonies.
Note that the formats may be the same for different formality scenarios depending on the length, usage, and cultural conventions for the locale. For example short formal and short informal may both be just the given name.
| Parameter | Description |
|---|---|
formal |
A more formal name for the individual. The composition depends upon the language. For example, a particular locale might include the title, generation, credentials and a full middle name (given2) in the long form.length="medium", formality="formal"“Robert J. Smith” |
informal |
A less formal name for the individual. The composition depends upon the language. For example, a language might exclude the title, credentials and given2 (middle) name. Depending on the length, it may also exclude the surname. The formatting algorithm should choose any passed in name data that has an informal attribute, if available.length="medium", formality="informal"“Bob Smith” |
A namePattern is composed of a sequence of field IDs, each enclosed in curly braces, and separated by zero or more literal characters (eg, space or comma + space). An Extended Backus Normal Form (EBNF) is used to describe the namePattern format for a specific set of attributes. It has the following structure. This is the ( #PCDATA ) reference in the element specification above.
| EBNF | Comments | |
|---|---|---|
| namePattern | = literal? ( modField literal? )+; |
Two literals cannot be adjacent |
| modField | = '{' field modifierList? '}'; | A name field, optionally modified |
| field | = 'title' | 'given' | 'given2' | 'surname' | 'surname2' | 'generation' | 'credentials' ; |
See Fields |
| modifierList | = '-informal'? ( '-allCaps' | ‘-initialCap' )?; ( '-initial' | '-monogram' )? ( '-prefix' | '-core' )? |
Optional modifiers that can be applied to name parts, see Modifiers. Note that some modifiers are exclusive: only prefix or core, only initial or monogram, only allCaps or initialCap. |
| literal | = codepoint+ ; | One or more Unicode codepoints. |
The Person Name formatting data assumes that the name data to be formatted consists of the fields in the table below. All of the fields may contain multiple words. Field IDs are lowercase ASCII alphanumeric, and start with an alphabetic character.
When determining how a full name is to be placed into name fields, the data to be formatted should be organized functionally. That is, if a name part is on the dividing line between given2 and given, the key feature is whether it would always occur with the rest of the given name. For example, in “Mary Jean Smith”, if “Mary” never occurs without the “Jean”, then the given name should be “Mary Jean”. If “Smith” never occurs without the “Jean”, the surname should be “Jean Smith”. Otherwise, “Jean” would be the given2 field.
For example, a patronymic would be treated as a given2 name in most slavic languages.
In some cultures, two surnames are used to indicate the paternal and maternal family names or generational names indicating father, grandfather. The surname2 field is used to indicate this. The CLDR PersonName formatting data assumes that if a PersonName object to be formatted does not have two surnames, then the surname2 field is not populated. (That is, no pattern should have a surname2 field without a surname field.) Order of fields in a pattern can vary arbitrarily by locale.
In most cultures, there is a concept of nickname or preferred name, which is used in informal settings or sometimes to represent a “public” or “stage name”. The nickname or preferred name may be submitted as a separate PersonName object to be formatted, or included with a modifier such as given-informal.
| Field | Description Note: The values for each are as supplied by the PersonName object, via the PersonName data interface. |
|---|---|
title |
A title or honorific qualifier. Example: ‘Ms.’, ‘Mr.’, ’Dr’, ‘President’ Note that CLDR PersonName formats data does not define regional or locale-specific lists of titles or honorifics such as “Mr”, “Ms”, “Mx”, “Prof”, etc. |
given |
The “given” name. Can be multiple words such as “Mary Ann”. Examples: “Janus”, “Mary Jean”, or “Jean-Louis” |
given2 |
Additional given name or names or middle name, usually names(s) written between the given and surname. Can be multiple words. In some references, also known as a “second” or “additional” given name or patronymic. This field is separate from the “given” field because it is often optional in various presentation forms. Examples: “Horatio Wallace” as in { given: "Janus", given2: "Horatio Wallace", surname: "Young" }“S.” as in “Harry S. Truman”. Yes, his full middle name was legally just “S.”. |
surname |
The “family name”. Can be more than one word. Example: “van Gogh” as in { given: "Vincent", given2: "Willem", surname: "van Gogh" }Other examples: “Heathcote-Drummond-Willoughby” as in “William Emanuel Heathcote-Drummond-Willoughby III” |
surname2 |
Secondary surname (used in some cultures), such as second or maternal surname in Mexico and Spain. This field is separate from the “surname” field because it is often optional in various presentation forms, and is considered a separate distinct name in some cultures. Example: “Barrientos” in “Diego Rivera Barrientos”; { given: "Diego", surname: "Rivera", surname2: "Barrientos" }Example: if "Mary Jane Smith" moves to Spain the new name may be { given: "Mary", given2: "Jane", surname: "Smith", surname2: "Jones" } |
credentials |
A credential or accreditation qualifier. Example: “PhD”, “MBA” Example: “Salvatore Jarvis MBA” { given: "Salvatore", given2: "Blinken", surname: "Jarvis", credentials: "MBA" }An alternate PersonName object may be presented for formatting using the “stage” name from the application’s data: { given: "Salvatore", given-informal: "Salvatore", given2: "", surname: "Jarvis", credentials: "MBA" } |
generation |
A generation qualifier. Example: “III”, “Jr.” Example: “Sonny Jarvis Jr.” { given: "Salvatore", given2: "Blinken", surname: "Jarvis", generation: "Jr." } |
Some other examples:
given name is "John", given2 name would be "Ronald Reuel", and the surame is "Tolkien".given name: "Anneliese", given2 name: "Louise", surname: "van der Pol"given) Louis (given2) Trintignant (surname), since “Louis” wouldn’t be discarded when formatting. Instead it would be Jean-Louis (given) Trintignant (surname)Note: If the legal name, stage name, etc. are substantially different, then that information can be logically in a separate PersonName object. That is, it is up to the implementation to maintain any distinctions that are important to it: CLDR PersonName formats is focusing on formatting a PersonName object that is given to it.
surname2 would only be asked for in certain locales, and where it is considered a separate, divisible name, such as in Mexico or Spain. For instance, in Mexico, the first and second surname are used for the legal name and in formal settings, and sometimes only the first surname is used in familiar or informal contexts.
{surname}-{surname2} because we would never discard part of the name when formatting.given name is “Jose”, the given2 name is “Luis”, the surname is "Garcia”, and the surname2 is “Barrientos"How names get placed into fields to be formatted is beyond the scope of CLDR PersonName formats; this document just lays out the assumptions the formatting code makes when formatting the names.
Each field in a pattern can have one or more modifiers. The modifiers can be appended to any field name, such as {given-initial} for the first grapheme of the given name. If more than one modifier is applied, they must be structured as in the EBNF.
The modifiers transform the input data as described in the following table:
| Modifier | Description |
|---|---|
| informal | Requests an informal version of the name if available. For example, {given} might be “Thomas”, and {given-informal} might be “Tom”. If there is no informal version, then the normal one is returned. An informal version should not be generated, because they vary too much: Beth, Betty, Betsy, Bette, Liz, … |
| prefix | Return the “prefix” name, or the “tussenvoegsel'' if present. For example, “van der Poel” becomes “van der”, “bint Fadi” becomes “bint”, “di Santis” becomes “di”. Note that what constitutes the prefix is language- and locale-sensitive. It may be passed in as part of the PersonName object, similar to the “-informal” modifier, e.g. as “surname-prefix”. The implementation of this modifier depends on the PersonName object. CLDR does not currently provide support for automatic identification of tussenvoegsels, but may in the future. If the resulting “-prefix” value is empty, it defaults to an empty string. An example sorting pattern for “Johannes van den Berg” may be {surname-core}, {given} {given2} {surname-prefix} Only the “-prefix” or the “-core” modifier may be used, but not both. They are mutually exclusive. |
| core | Return the “core” name, removing any tussenvoegsel. For example, “van der Poel” becomes “Poel”, “bint Fadi” becomes “Fadi”, “di Santis” becomes “Santis”. Note that what constitutes the core is language- and locale-sensitive. The implementation of this modifier depends on the PersonName object. CLDR does not currently provide support for identification of tussenvoegsel, but may in the future. If the resulting “-core” value is empty, it defaults to the field it modifies. E.g., if “surname-core” is empty in the PersonName object to be formatted, it will default to the “surname” field. Vice-versa, if the surname field is empty, the formatter will attempt to use surname-prefix and surname-core, if present, to format the name. Only the “-prefix” or the “-core” modifier may be used, but not both. They are mutually exclusive. |
| allCaps | Requests the element in all caps, which is desired In some contexts. For example, a new guideline in Japan is that for the Latin representation of Japanese names, the family name comes first and is presented in all capitals. This would be represented as “{surname-allCaps} {given}” Hayao Miyazaki (宮崎 駿) would be represented in Latin characters in Japan (ja-Latn-JP) as “MIYAZAKI Hayao” The default implementation uses the default Unicode uppercase algorithm; if the PersonName object being formatted has a locale, and CLDR supports a locale-specific algorithm for that locale, then that algorithm is used. The PersonName object can override this, as detailed below. Only the “-allCaps” or the “-initalCap” modifier may be used, but not both. They are mutually exclusive. |
| initialCap | Request the element with the first grapheme capitalized, and remaining characters unchanged. This is used in cases where an element is usually in lower case but may need to be modified. For example in Dutch, the name { title: “dhr.”, given: ”Johannes”, surname: “van den Berg” }, when addressed formally, would need to be “dhr. Van den Berg”. This would be represented as “{title} {surname-initialCap}” Only the “-allCaps” or the “-initalCap” modifier may be used, but not both. They are mutually exclusive. |
| initial | Requests the initial grapheme cluster of each word in a field. The initialPattern patterns for the locale are used to create the format and layout for lists of initials. For example, if the initialPattern types are<initialPattern type="initial">{0}.</initialPattern><initialPattern type="initialSequence">{0} {1}</initialPattern>then a name such as { given: “John”, given2: “Ronald Reuel”, surname: “Tolkien” } could be represented as “{given-initial-allCaps} {given2-initial-allCaps} {surname}” and will format to “J. R. R. Tolkien” The default implementation uses the first grapheme cluster of each word for the value for the field; if the PersonName object has a locale, and CLDR supports a locale-specific grapheme cluster algorithm for that locale, then that algorithm is used. The PersonName object can override this, as detailed below. Only the “-initial” or the “-monogram” modifier may be used, but not both. They are mutually exclusive. |
| monogram | Requests initial grapheme. Example: A name such as { given: “Landon”, given2: “Bainard Crawford”, surname: “Johnson” } could be represented as “{given-monogram-allCaps}{given2-monogram-allCaps}{surname-monogram-allCaps}” or “LBJ” The default implementation uses the first grapheme cluster of the value for the field; if the PersonName object has a locale, and CLDR supports a locale-specific grapheme cluster algorithm for that locale, then that algorithm is used. The PersonName object can override this, as detailed below. The difference between monogram an initial is that monogram only returns one element, not one element per word. Only the “-initial” or the “-monogram” modifier may be used, but not both. They are mutually exclusive. |
| retain | This is needed in languages that preserve punctuation when forming initials. For example, normally the name {given=Anne-Marie} is converted into initials with {given-initialCaps} as “A. M.”. However, where a language preserves the hyphen, the pattern should use {given-initialCaps**-retain**} instead. In that case, the result is “A.-M.”. (The periods are added by the pattern-initialSequence.) |
| genitive, vocative | Patterns can use these modifiers so that better results can be obtained for inflected languages. However, see the details below. |
The CLDR person name formatting does not itself support grammatical inflection. However, name sources (NameObject) can support inflections, either by having additional fields or by using an inflection engine that can handle personal name parts.
In the current release, the focus is on supporting referring and addressing forms.
Typically the referring forms will be in the most neutral (nominative) case, and the addressing forms will be in the vocative case.
Some modifiers have been added to facilitate this, so that there can be patterns like: {given-vocative} {surname-vocative}.
Notice that some parts of the formatted name may be in different grammatical cases, so the cases may not be consistent across the whole name. For example:
| English Pattern | Examples | Latvian Pattern | Examples |
|---|---|---|---|
| {given} {surname} | John Smith | {given} {surname} | Kārlis Ozoliņš |
| {title} {surname} | Mr Smith | {surname} {title} | Ozoliņa kungs |
Notice that the surname in Latvian needs to change to the genitive case with that pattern:
Ozoliņš ➡︎ Ozoliņa
That is accomplished by changing the pattern to be {surname-genitive} {title}. In this case the {surname} should only be genitive if followed by the {title}.
Additional modifiers may be added in future versions of CLDR.
Examples:
{surname-initial} to:{surname-prefix-initial}{surname-core-initial-allCaps} to get “dS” instead of “d”.{surname-core} then {surname-prefix} would be used as in{surname-core}, {given} {given2} {surname-prefix}referring or addressing have been added as yet, but additional grammatical modifiers may be added in the future.The patterns are in personName elements, which are themselves in a personNames container element. The following describes how the formatter's locale interacts with the personName's locale, how the name patterns are chosen, and how they are processed.
The details of the XML structure behind the data referenced here are in XML Structure.
The formatting process may be refined in the future. In particular, additional data may be added to allow further customization.
The term maximal likely locale used below is the result of using the Likely Subtags data to map from a locale to a full representation that includes the base language, script, and region.
Construct the name script in the following way.
Construct the name base language in the following way.
Construct the name locale in the following way:
Construct the name ordering locale in the following way:
Let the full formatting locale be the maximal likely locale for the formatter's locale. The formatting base language is the base language (first subtag) of the full formatting locale, and the formatting script is the script code of the full formatting locale.
A few script values represent a set of scripts, such as Jpan = {Hani, Kana, Hira}. Two script codes are said to match when they are either identical, or one represents a set which contains the other, or they both represent sets which intersect. For example, Hani and Jpan match, because {Hani, Kana, Hira} contains Hani.
If the name script doesn't match the formatting script:
For example, when a Hindi (Devanagari) formatter is called upon to format a name object that has the locale Ukrainian (Cyrillic):
To determine whether there is name formatting data for a locale, get the values for each of the following paths. If at least one of them doesn’t inherit their value from root, then the locale has name formatting data.
A PersonName object’s fields are used to derive an order, as follows:
preferredOrder field, then return that field’s value* For example, here is a parent locale lookup chain:
de_Latn_DE ⇒ de_Latn ⇒ de_DE ⇒ de ⇒ und
In other words, with the name locale of de_Latin_DE you'll check the givenFirst and surnameFirst resources for the following locales, in this order:
de_Latin_DE, und_Latn_DE, de_Latn, und_Latn, de_DE, und_DE, de, und
This process will always terminate, because there is always a und value in one of the two nameOrderLocales elements. Remember that the lookup chain requires use of the parentLocales elements: it is not just truncation.
For example, the data for a particular locale might look like the following:
<nameOrderLocales order="surnameFirst">zh ja und-CN und-TW und-SG und-HK und-MO und-HU und-JP</nameOrderLocales>
These nameOrderLocales will match any locale with a zh or ja unicode_language_subtag and any locale with a CN, TW, SG, HK MO, HU, or JP unicode_region_subtag.
Here are some more examples. Note that if there is no order field or locale field in the PersonName object to be formatted, and the script of the PersonName data is different from that of the formatting locale, then the default result is givenFirst.
| PersonName Object preferredOrder | PersonName Object Locale | Resulting Order |
|---|---|---|
| surnameFirst | ? | surnameFirst |
| zh | surnameFirst | |
| und-JP | surnameFirst | |
| fr | givenFirst | |
| givenFirst |
The personName data in CLDR provides representations for how names are to be formatted across the different axes of order, length, usage, and formality. More than one namePattern can be associated with a single personName entry. An algorithm is then used to choose the best namePattern to use.
As an example for English, this may look like:
<personNames>
<personName order="givenFirst" length="long" usage="referring" formality="formal">
<namePattern>{title} {given} {given2} {surname}, {credentials}</namePattern>
</personName>
<personName order="givenFirst" length="long" usage="referring" formality="informal">
<namePattern>{given} «{given2}» {surname}</namePattern>
<namePattern alt="2">«{given2}» {surname}</namePattern>
</personName>
<personName order="givenFirst" length="long" usage="sorting" formality="informal">
<namePattern>{surname}, {given} {given2}</namePattern>
</personName>
...
</personNames>
The task is to find the best personName for a given set of input attributes. Well-formed data will always cover all possible combinations of the input parameters, so the algorithm is simple: traverse the list of person names until the first match is found, then return it.
In more detail:
A set of input parameters { order=O length=L usage=U formality=F } matches a personName element when:
Example for input parameters
order =givenFirst, length =long, usage =referring, formality =formal
To match a personName, all four attributes in the personName must match (a missing attribute matches any value for that attribute):
| Sample personName attributes | Matches? | Comment |
|---|---|---|
order="givenFirst" length="long" usage="referring" formality="formal" |
Y | exact match |
length="long" usage="referring" formality="informal" |
N | mismatch for formality |
length="long" formality="formal" |
Y | missing usage = all! |
To find the matching personName element, traverse all the personNames in order until the first one is found. This will always terminate since the data is well-formed in CLDR.
To format a name, the fields in a namePattern are replaced with fields fetched from the PersonName Data Interface. The personName element can contain multiple namePattern elements. Choose one based on the fields in the input PersonName object that are populated:
For example:
All PersonName objects will have a given name (for mononyms the given name is used). However, there may not be a surname. In that case, the following process is followed so that formatted patterns produce reasonable results.
As always, this is a logical description and may be optimized in implementations. For example, an implemenation may use an interface for P2 that just delegates calls to P1, with some redirection for accesses to surname and given name.
A given field may have a core value, a prefix value, and/or a ‘plain’ value (neither core nor prefix). If one or more of them are missing, then the returned values should be adjusted according to the table below. In the three cells on the left, a ✓ indicates that a value is available, an ✖️ if there is none. In three cells on the right, the value of = means the returned value is unchanged, ✖️ means the returned value is “empty”, and anything else is a description of what to change it to.
| prefix | core | plain | prefix | core | plain | |
|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | = | = | = | |
| ✓ | ✖️ | ✓ | ✖️ | plain | = | |
| ✖️ | ✓ | ✓ | = | plain | = | |
| ✖️ | ✖️ | ✓ | = | plain | = | |
| ✓ | ✓ | ✖️ | = | = | prefix + " " + core | |
| ✖️ | ✓ | ✖️ | = | = | core | |
| ✓ | ✖️ | ✖️ | ✖️ | = | = | |
| ✖️ | ✖️ | ✖️ | = | = | = |
For example, if the surname-prefix is "von und zu" and the surname-core is "Stettbach" and there is no surname (plain), then the derived value for the (plain) surname is "von und zu Stettbach". (The cases where existing prefix values are changed should not be necessary with well-formed PersonName data.)
The following process is used to produce initials when they are not supplied by the PersonName object. Assuming the input example is “Mary Beth”:
| Action | Result |
|---|---|
| 1. Split into words | “Mary” and “Beth” |
| 2. Fetch the first grapheme cluster of each word | “M” and “B” |
3. The initial pattern is applied to each <initialPattern type="initial">{0}.</initialPattern> |
“M.” and “B.” |
4. Finally recombined with initialSequence <initialPattern type="initialSequence">{0} {1}</initialPattern> |
“M. B.” |
See the “initial” modifier in the Modifiers section for more details.
The “winning” namePattern may still have fields that are unpopulated (empty) in the PersonName object. That namePattern is populated with field values with the following steps:
The result is the formatted value. However, there is one further step that might further modify that value.
There are two main challenges in dealing with foreign name formatting that needs to be considered. One is the ordering, which is dealt with under the section nameOrderLocales Element]. The other is spacing.
Some writing systems require spaces (or some other non-letters) to separate words. For example, Hayao Miyazaki is written in English with given name first and with a space between the two name fields, while in Japanese there is no space with surname first: 宮崎駿
If a locale requires spaces between words, the normal patterns for the formatting locale are used. On Wikipedia, for example, note the space within the Japanese name on pages from English and Korean (an ideographic space is used here for emphasis).
If a locale doesn’t require spaces between words, there are two cases, based on whether the name is foreign or not (based on the PersonName objects explicit or calculated locale's language subtag). For example, the formatting locale might be Japanese, and the locale of the PersonName object might be de_CH, German (Switzerland), such as Albert Einstein. When the locale is foreign, the foreignSpaceReplacement is substituted for each space in the formatted name. When the name locale is native, a nativeSpaceReplacement is substituted for each space in the formatted name. The precise algorithm is given below.
Here are examples for Albert Einstein in Japanese and Chinese:
foreignSpaceReplacement element; the default value is a SPACE (" ").nativeSpaceReplacement element; the default value is SPACE (" ").For the purposes of this algorithm, two base languages are said to match when they are identical, or if both are in {ja, zh, yue}.
Note: in the future the plan is to make the specific languages and scripts used in this algorithm be data-driven.
Remember that a name in a different script will use a different locale for formatting, as per Switch the formatting locale if necessary. For example, when formatting a name for Japanese, if the name is in the Latin script, a Latin based locale will be used to format it, such as when “Albert Einstein” appears in Latin characters as in the Wikipedia page Albert Einstein.
To illustrate how foreign space replacement works, consider the following name data. For illustration, the name locale is given in the maximized form: in practice, ja would be used instead of ja_Jpan_JP, and so on.: For more information, see Likely Subtags.
| name locale | given | surname |
|---|---|---|
de_Latn_CH |
Albert | Einstein |
de_Kata_CH |
アルベルト | アインシュタイン |
ja_Kata_CH |
アルベルト | アインシュタイン |
ja_Latn_JP |
Hayao | Miyazaki |
ja_Jpan_JP |
駿 | 宮崎 |
Suppose the PersonNames formatting patterns for ja_JP and de_CH contained the following:
ja_JP formatting patterns
<personNames> <nameOrderLocales order="givenFirst">und</nameOrderLocales> <nameOrderLocales order="surnameFirst">hu ja ko vi yue zh und_JP</nameOrderLocales> <nativeSpaceReplacement xml:space="preserve"></nativeSpaceReplacement> <foreignSpaceReplacement xml:space="preserve">・</foreignSpaceReplacement> . . . <personName order="givenFirst" length="medium" usage="referring" formality="formal"> <namePattern>{given} {given2} {surname}{generation}</namePattern> </personName> . . . <personName order="surnameFirst" length="medium" usage="referring" formality="formal"> <namePattern>{surname}{given2}{given}{generation}</namePattern> </personName> . . . </personNames>
Note in the de_CH locale, ja is not listed in nameOrderLocales, and would therefore fall under und, and be formatted using the givenFirst order patterns if the name data is in the same script as the formatting locale.
de_CH formatting patterns
<personNames> <nameOrderLocales order="givenFirst">und de</nameOrderLocales> <nameOrderLocales order="surnameFirst">ko vi yue zh</nameOrderLocales> <foreignSpaceReplacemen xml:space="preserve"> </foreignSpaceReplacement> . . . <personName order="givenFirst" length="medium" usage="referring" formality="formal"> <namePattern>{given} {given2-initial} {surname}, {generation}</namePattern> </personName> . . . <personName order="surnameFirst" length="medium" usage="referring" formality="formal"> <namePattern>{surname}, {given} {given2-initial}, {generation}</namePattern> </personName> . . . </personNames>`
The name data would resolve as follows:
| formatting locale: ja_JP, script is Jpan which includes Hani, Hira and Kana | ||||||
| name locale | given | surname | same script |
formatting locale | order | foreign space |
| de_Latn_CH | Albert | Einstein | NO | de | given First | |
| “Albert Einstein” | ||||||
| de_Jpan_CH | アルベルト | アインシュタイン | YES | und | given First | “・” |
| “アルベルト・アインシュタイン” | ||||||
| ja_Jpan_JP | 駿 | 宮崎 | YES | ja | surname First | |
| 宮崎駿 | ||||||
| formatting locale: de_CH, formatting locale script is Latn | ||||||
| name locale | given | surname | same script |
formatting locale |
order | foreign space |
| de_Latn_CH | Albert | Einstein | YES | de | given First | |
| “Albert Einstein” | ||||||
| de_Jpan_CH | アルベルト | アインシュタイン | NO | ja from script |
given First | “・” |
| “アルベルト・アインシュタイン” | ||||||
| und_Latn_JP | Hayao | Miyazaki | YES | und | given First | “ ” |
| “Hayao Miyazaki” | ||||||
The personName element contains:
<namePattern>{title} {given} {given2} {surname}, {credentials}</namePattern>
The input PersonName object contains:
title |
given |
given2 |
surname |
generation |
|---|---|---|---|---|
| Raymond | J. | Johnson | Jr. |
The output is:
Raymond J. Johnson, Jr.
The “title” field is empty, and so both it and the space that follows it are omitted from the output, according to rule 1 above.
If, instead, the input PersonName object contains:
title |
given |
given2 |
surname |
generation |
|---|---|---|---|---|
| Raymond | J. | Johnson |
The output is:
Raymond J. Johnson
The “title” field is empty, and so both it and the space that follows it are omitted from the output, according to rule 1 above.
The “generation” field is also empty, so it and both the comma and the space that precede it are omitted from the output, according to rule 2 above.
To see how rule 3 interacts with the other rules, consider an imaginary language in which people generally have given and given2 (or middle) names, and the given2 name is always written with parentheses around it, and the given name is usually written as an initial with a following period.
The personName element contains:
<namePattern>{given-initial}. ({given2}) {surname}</namePattern>
The input PersonName object contains:
given |
given2 |
surname |
|---|---|---|
| Foo | Bar | Baz |
The output is:
F. (Bar) Baz
If, instead, the input PersonName object contains:
given |
given2 |
surname |
|---|---|---|
| Foo | Baz |
The output is:
F. Baz
The “given2” field is empty, so it and the surrounding parentheses are omitted from the output, as is one of the surrounding spaces, according to rule 3. The period after “{given-initial}” remains, because it is separated from the “{given2}” element by space-- punctuation around a missing field is only deleted up until the closest space in each direction.
If there were no space between the period and the parentheses, as might happen if our hypothetical language didn’t use spaces:
<namePattern>{given-initial}.({given2}) {surname}</namePattern>
The input PersonName object still contains:
given |
given2 |
surname |
|---|---|---|
| Foo | Baz |
The output is:
F Baz
Both the period after “{given-initial}” and the parentheses around “{given2}” are omitted from the output, because there was no space between them — instead, we delete punctuation all the way up to the neighboring field. To solve this (making sure the “{given-initial}” field always has a period after it), you would add another namePattern:
<namePattern>{given-initial}.({given2}) {surname}</namePattern>
<namePattern alt=”2”>{given-initial}. {surname}</namePattern>
The first pattern would be used when the “given2” field is populated, and the second pattern would be used when the “given2” field is empty.
Rules 1 and 3 can conflict in similar ways. If the personName element contains (there’s a space between the period and the opening parenthesis again):
<namePattern>{given-initial}. ({given2}) {surname}</namePattern>
And the input PersonName object contains:
given |
given2 |
surname |
|---|---|---|
| Bar | Baz |
The output is:
Bar) Baz
Because the “given” field is empty, rule 1 not only has us delete it, but also all punctuation up to “{given2}”. This includes both the period and the opening parenthesis. Again, to solve this, you’d supply two namePatterns:
<namePattern>{given-initial}. ({given2}) {surname}</namePattern>
<namePattern alt=”2”> ({given2}) {surname}</namePattern>
The output would then be:
(Bar) Baz
The first namePattern would be used if the “given” field was populated, and the second would be used if it was empty.
If, instead, the input PersonName object contains:
given |
given2 |
surname |
|---|---|---|
| Foo | Baz |
The output is:
F. Baz
The sampleName element is used for test names in the personNames LDML data for each locale to aid in testing and display in the CLDR Survey Tool. They are not intended to be used in production software as prompts or placeholders in a user interface and should not be displayed in a user interface.
<!ELEMENT sampleName ( nameField+ ) >
<!ATTLIST sampleName item NMTOKEN #REQUIRED >
NMTOKEN must be one of ( nativeG, nativeGS, nativeGGS, nativeFull, foreignG, foreignGS, foreignGGS, foreignFull ). However, these may change arbitrarily in the future.The item values starting with "native" are expected to be native names, in native script. The item values starting with "foreign" are expected to be foreign names, in native script. There are no foreign names or native names in a foreign script, because those should be handled by a different locale's data.
The rest of the item value indicates how many fields are present. For the expected sample name items, assume a name such as Mr. Richard “Rich” Edward Smith Iglesias Ph.D.
G is for an example name with only the given is presented: “Richard” or “Rich” (informal)GS is for an example name with only the given name and surname: “Richard Smith” or “Rich Smith” (informal)GSS is for an example using both given and given2 names and a surname: “Richard Edward Smith” and “Rich E. Smith” (informal)Full is used to present a name using all possible fields: “Mr. Richard Edward Smith Iglesias, Ph.D.”The nameField values and their modifiers are described in the Person Name Object and namePattern Syntax sections.
When implementations allow entry of person names, they are often too strict; there are many instances where people can’t enter their real names, such as O’Brian, Stéphanie, Wałęsa, Þjóðólfr. Conversely, when an implementation is too lenient, it allows names like Ȟěl̀a, or B🅾️b. (See also Zalgo.)
Sometimes the constraints are imposed by limitations of outdated software or databases (such as not supporting Unicode character), or legal restrictions (such as only accepting names legal in Switzerland on native Swiss passports).
However, when the limitations are due to unfamiliarity with the kinds of characters that can appear in languages, Unicode properties and CLDR data can help implementers to avoid being either too strict or too lenient.
A common restriction is that the letters in a name only come from a single script. That may be too lenient: there are over 1,453 letters in the Latin script in Unicode 17!
To narrow it down, an implementation may form the union of exemplar characters from a set of languages in CLDR (together with their uppercase equivalents); these include letters and combining marks (accents). Here are some examples:
| Language | Exemplars (Main) |
|---|---|
| Icelandic | a á b d ð e é f g h i í j k l m n o ó p r s t u ú v x y ý þ æ ö |
| Polish | a ą b c ć d e ę f g h i j k l ł m n ń o ó p r s ś t u w y z ź ż |
| Arabic | ً ٌ ٍ َ ُ ِ ّ ْ ٰ ء أ ؤ إ ئ ا آ ب ة ت ث ج ح خ د ذ ر ز س ش ص ض ط ظ ع غ ف ق ك ل م ن ه و ى ي |
| Urdu | ا ب پ ت ٹ ث ج چ ح خ د ڈ ذ ر ڑ ز ژ س ش ص ض ط ظ ع غ ف ق ک گ ل م ن و ہ ھ ء ی ے |
There are also auxiliary exemplars (in the same script) that should be included, that are not part of the core alphabet, but are in use (typically loan words or names). For example, in English someone would not be surprised to see a name such as René or Schröder.
| Language | Exemplars (Auxilliary) |
|---|---|
| Polish (aux) | à â å ä æ ç é è ê ë î ï ô ö œ q ß ù û ü v x ÿ |
It is often useful to explicitly include the exemplars from multiple languages. For example, an implementation may choose to include the exemplars from official languages of the EU, or for major languages of Africa. There is data in CLDR for the populations of languages in countries, and their official status, that may be useful for this.
Names, even for a single name field like the family name, may have spaces, such as “de Silva”. Some additional punctuation characters commonly used in names are provided by the punctuation-person exemplars.
| Polish (punct-person) | , . - / |
|---|
Those may include some variants of the ASCII hyphen; typically the best approach is to normalize them as below.
Examples include: Jean-Luc; Dr. Doom; James Smith Jr., MD
When names are input from the keyboard, they should be normalized before validation. Typically the best foundation for that is Unicode NFC format. Additional useful normalizations are
Other useful constraints include testing for extremely unusual cases, which may be mistakes or jokes (Zalgo). For these it is helpful to transform first into NFD, then apply the tests.
For further information, including confusables, mixed script detection, and so on, see UTS #39: Unicode Security Mechanisms.
Greek initials can be produced via the following process in the PersonName object, and returned to the formatter.
Examples:
To make an initial when there are multiple words, an implementation might produce the following:
© 2001–2026 Unicode, Inc. This publication is protected by copyright, and permission must be obtained from Unicode, Inc. prior to any reproduction, modification, or other use not permitted by the Terms of Use. Specifically, you may make copies of this publication and may annotate and translate it solely for personal or internal business purposes and not for public distribution, provided that any such permitted copies and modifications fully reproduce all copyright and other legal notices contained in the original. You may not make copies of or modifications to this publication for public distribution, or incorporate it in whole or in part into any product or publication without the express written permission of Unicode.
Use of all Unicode Products, including this publication, is governed by the Unicode Terms of Use. The authors, contributors, and publishers have taken care in the preparation of this publication, but make no express or implied representation or warranty of any kind and assume no responsibility or liability for errors or omissions or for consequential or incidental damages that may arise therefrom. This publication is provided “AS-IS” without charge as a convenience to users.
Unicode and the Unicode Logo are registered trademarks of Unicode, Inc. in the United States and other countries.